

To err is human!

Below is a list of infamous outages, which occurred due human error:
- AWS S3 Outage Feb 28th 2017: “an authorized S3 team member…one of the inputs to the command was entered incorrectly”
[source: https://aws.amazon.com/message/41926/] - Knight Capital Group $440m glitch: “The incident happened due to a technician forgetting to copy the new Retail Liquidity Program (RLP) code to one of the eight…computer servers” [source: https://en.wikipedia.org/wiki/Knight_Capital_Group]
- Royal Bank of Scotland fined £56m over computer failure: “A software update was applied on 19 June 2012 to payment processing system….later emerged that the update was corrupted by RBS technical staff.” [source: https://en.wikipedia.org/wiki/2012_RBS_Group_computer_system_problems]
- Target 40 Million Stolen Credit Card Numbers “Bangalore got an alert and flagged the security team in Minneapolis. And then … Nothing happened…” [source: https://www.bloomberg.com/news/articles/2014-03-13/target-missed-warnings-in-epic-hack-of-credit-card-data]
The list above could be made longer than “a one mile scroll”, but it illuminates the reasons that organizations must make investment in automation. Lack of automation leads to human error, which directly contributes to a variety of operational outages/impediments, such as downtime, performance, deployment life-cycle latency and many other issues; these issues cost money or in the case of Knight Capital cost the entire company!
Money is to business as our sun is to Earth. How can you survive? Enter the continuous automation pipeline…

CI -> CD -> CD – Rinse, Repeat,…
Today, most teams have a mature Continuous Integration (CI) process, whereby developers are required to
integrate their code into a shared repository (git, SVN, etc) several times a day. Each check-in or commit is then verified by an automated build that will exercise unit tests against the code. This practice allows teams to detect problems early and fix them quickly. While this is an integral piece and highly beneficial to code quality and speed, it is only the first step; further automation is needed.
The next stage of the pipeline is Continuous Delivery (CD). CD is a software development discipline where you build software, in such a way, that the software can be released to production at any time with low risk. This risk mitigation becomes possible, because automated tooling exists, which vets the readiness of the software before it’s delivered. (Please note that if you have a hardening phase, this is not Continuous Delivery!) Do not confuse Continuous Delivery with Continuous Deployment.
With Continuous Deployment every change that goes through the pipeline will automatically get placed into production, resulting in many production deployments every day. Keep in mind, these deployments must have successfully passed through all the automated pipeline hurdles, before they will be candidates for deployment. If at any point during the pipeline, a failure is detected – like Monopoly – you must go the the beginning without collecting your $200. Achieving Continuous Deployment is the holy grail. It is difficult to attain, but immeasurable in terms of its impact to speed, quality and opportunity. Remember that solutions generally don’t deliver business value until they are deployed, so the faster that we deploy, the faster we get to business value. QED.
In the CI/CD pipeline every time there is a code commit, it is built and tested automatically (unit tests, regression tests, code analysis, security scans, etc.). If it passes the various quality control gates and all the tests pass, then it is automatically deployed, where automated acceptance tests run against it. As noted above, if at any stage anything goes wrong, then the pipeline aborts or is rolled back. This iterative approach will initially fail often and be painful, but as a result, it will get the attention it needs and will reach a point of confidence, where failure is the exception not the rule.
It’s important that R&D continuously invest in all aspects of the CI/CD.
“You get what you design for. Chester, your peer in Development, is spending all his cycles on features, instead of stability, security, scalability, manageability, operability, continuity, and all those other beautiful ’itties.” ― Gene Kim, The Phoenix Project: A Novel About IT, DevOps, and Helping Your Business Win
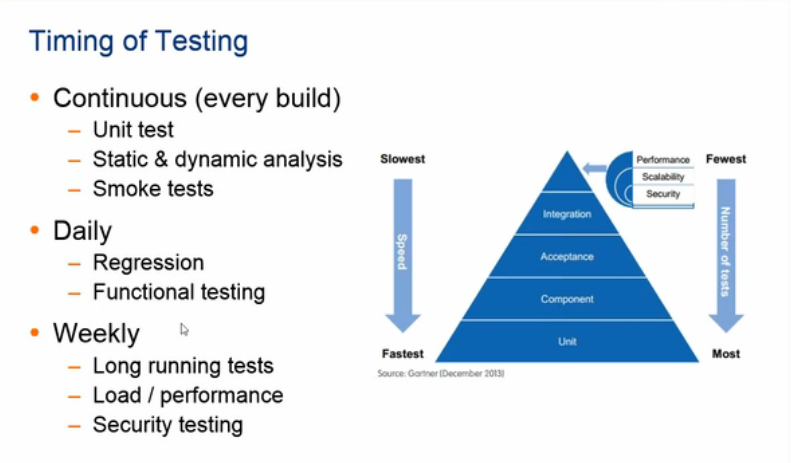
You should aim to automate everything and make sure that we can CD in minutes. To achieve this, a mindset / cultural change is required whereby continuously deploying becomes the companies heartbeat (https://blog.intercom.com/shipping-is-your-companys-heartbeat/). To achieve this speed, it important to remember the testing pyramid, so you can determine what needs to be run on check-ins etc.
[source: https://www.coveros.com]
What about failure?
“Everything fails, all the time” – W Vogels, Amazon CTO
We know that humans make mistakes, but systems can fail too. We need to build our systems for failure. How confident would we be to release the Simian Army into our managed services infrastructure? How robust are our systems? Most of our systems can handle connection failures, but what about connects that are slow, or returning unexpected content or error codes? Have we adopted libraries and patterns, like in Hystrix, that help make our systems more resilient to failure? Do we have infrastructure as code to make are infrastructure repeatable? Or are we surrounded by snowflake servers? Are our servers stateless so that we can adopt immutable infrastructure?
One of the anti-patterns we have today is when we require changes (patch, service pack, configuration change) – then our services encounter downtime. With CD, we will be releasing frequently, with every commit to master, therefore we cannot afford these outages. We need these changes to be able to get applied to production without any downtime of the service. Email notification of a depending service outage are a thing of the past and should be seen as an anti-pattern. We either need to change our products to allow updates without downtime or adopt deployment mechanisms, like blue green which facilitates zero downtime. Remember, when we are a SaaS, any outage would be unacceptable and would violate our SLA.
“Organizations that deliver at rapid release cycles create a stable basis for funding a continuous stream of innovation. They use customer feedback and business priorities to continuously prioritize the capabilities that will result in the greatest business value.” – Forrester
If we achieve CD, then it’s possible that we can find new ways to get feedback. Say, if we come up with a cool new feature, we could create a simple version of it first and deploy it behind a feature flag and gain insights on its usage from internal users. We refine the feature before providing it to early adopters, and then finally it could make it into the product properly. Having this feedback loop is invaluable, and we try and use it for everything we build. At each stage in this process, we learn more about how people use the feature, how the code performs in production, even whether it’s a cool feature at all. Compare this to the feedback cycle we have today, where the time it takes from feature inception to feature consumption, by a customer, could easily be greater than a year!
[source: https://arcadsoftware.com]
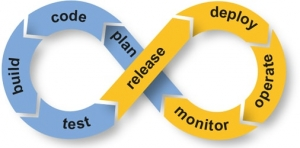
If we reach the CI/CD nirvana, then you quickly realise that the system is not a pipeline, but is, in fact, an infinite loop, whereby we end up in a position to make data-driven decisions in order to improve or remove capabilities.
People reading this blog will think that various items that I’ve discussed here are only for R&D.
With Axway R&D, we need to introduce automation tools to ease the promotion process for changes into upper environments, and ultimately into production. We need to remove anything that is slow, unresponsive, cumbersome, manual and prone to error. If our systems are slow, then it is human nature to work around the problem, rather than to address the problem head on.

With our products, we need to look at the “infinite” loop of CI/CD, and provide the tooling and support to help our customers as they spin through this. Do we provide the tools / integrations which show that any change is good? Do we have the tools to help with promotion through various environments? Are our products instrumented correctly, so that our customers can make changes?
To adopt devops automation, not only do we need to evolve, but also the products that we produce need to evolve!
But a word of warning, make sure you have you guard rails in place as:
Stay tuned for my next blog: L is for Lean. And, here are the other blogs in this series: