


En juin dernier, j’ai eu l’honneur de prononcer une allocution à Nexus Luxembourg 2025. C’est la première fois qu’Axway participe à cette conférence, qui en est à sa deuxième année et qui se concentre sur l’accélération de l’IA et de l’innovation dans la technologie. Mes collègues Jeroen Delbarre et Hamdi Arous ont également présenté Amplify Fusion, et nous avons trouvé cet événement inspirant, avec de nombreux leaders du secteur.
Il est essentiel de fournir des données à l’IA de manière fiable et sécurisée. Alors que beaucoup se concentrent sur la qualité des données pour l’utilisation de l’IA et les questions de souveraineté en jeu, je vois peu de discussions sur l’infrastructure et la gestion nécessaires, ou sur la manière d ‘obtenir ces données de qualité pour les modèles d’IA à l’échelle.
C’est là qu’Axway intervient.
L’analogie entre les données et l’eau permet d’illustrer la situation de manière facile à comprendre, alors plongeons dans ce que j’aime appeler ” l’intelligence liquide ”
Comme l’eau nous donne la vie, les données donnent la vie à l’IA
L’eau, comme les données, est partout. Elle coule d’un endroit à l’autre. Elle est mesurée, surveillée et traitée pour en améliorer la qualité en cours de route.
Il n’y a pas si longtemps, les systèmes avaient des architectures de données bien structurées. Si vous aviez besoin d’allumer une application web, il vous suffisait d’allumer un LAMP. Aujourd’hui, nos données proviennent de beaucoup plus de sources et sont retransmises, mises en cache, enrichies et filtrées.
Des appareils IoT aux téléphones mobiles, les données que nous devons inspecter ne sont pas collectées dans un seul pool d’un serveur LAMP, mais dans les nombreuses flaques, piscines, lacs et océans de nos parcs de données d’entreprise.
- À l’âge de 20 ans, un être humain a entendu 150 millions de mots. Le GPT-4 a vu 5 billions de mots à la naissance
- L’IA a besoin de données pour survivre. Et elle ne se contente pas de siroter, elle engloutit !
De plus, la genAI n’attend pas que les données soient joliment collectées dans un bassin bien ordonné. Nous devons trouver le moyen d’acheminer les données de l’endroit où elles se trouvent à l’endroit où elles doivent se trouver, d’une manière sûre, évolutive et efficace.
Tout comme l’approvisionnement en eau d’une ville, la protection de l’intégrité et de la sécurité des données ne dépend pas seulement de l’endroit où elles se trouvent, mais aussi de la façon dont elles se déplacent. L’un des défis actuels consiste à gérer ce flux : consolider certaines données, diviser ou acheminer d’autres données à travers des pools multiples, parfois fédérés.
Pour y parvenir efficacement, vous devez savoir exactement où se trouvent vos données, où elles doivent aller et comment les déplacer en toute sécurité et avec une gouvernance appropriée.
Sans données fiables et bien gouvernées en mouvement, votre IA ne peut pas fonctionner.
La plomberie n’est pas nécessairement l’analogie la plus flashy pour le monde enivrant de l’IA, mais elle est tout à fait appropriée. L’infrastructure requise ressemble beaucoup aux systèmes d’aqueducs, sans lesquels Rome n’aurait pu construire ni bains, ni forums, ni avenir.
Auparavant, la gravité des données permettait de tout réunir. Aujourd’hui, c’est la gouvernance qui les sépare
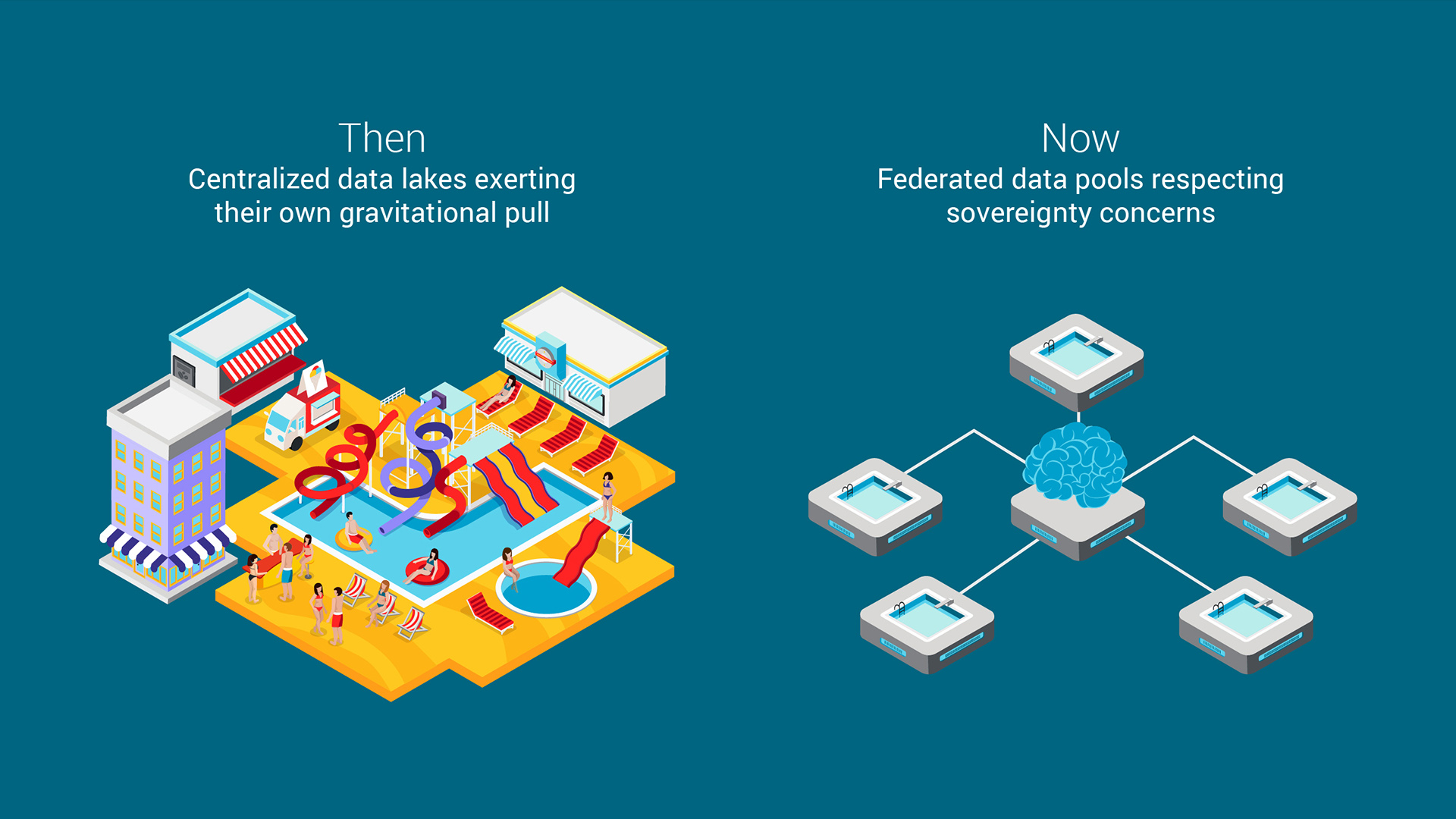
Lacs de données centralisés
Dans le passé, les entreprises cherchaient à rassembler toutes leurs données dans un référentiel massif et centralisé – un “lac de données” La taille et la valeur de ces données créaient une attraction gravitationnelle : les applications, les services et les outils d’analyse se regroupaient autour d’elles, un peu comme les magasins et les restaurants se rassemblent autour d’un parc d’attractions populaire. Cet effet est connu sous le nom de “gravité des données” : plus il y a de données au même endroit, plus il y a de choses à y faire.
Pools de données fédérés
Aujourd’hui, ce modèle de centralisation est en train de s’effondrer. En raison de la gouvernance des données, des lois sur la protection de la vie privée et des problèmes de souveraineté, les données ne peuvent souvent pas être déplacées ou regroupées au-delà des frontières ou des systèmes. Au lieu d’un lac géant, nous gérons aujourd’hui de nombreux pools distribués, chacun régi par ses propres règles. Plutôt que de déplacer toutes les données vers un seul endroit, nous construisons des systèmes qui permettent à l’intelligence de circuler entre eux, tout en conservant les données là où elles sont légalement et/ou éthiquement déterminées à appartenir.
Préoccupations énergétiques
Nous serions négligents si nous n’abordions pas le sujet de l’énergie. Tout comme l’eau ne peut pas circuler dans les canalisations des villes d’aujourd’hui par la seule gravité, les données ne le peuvent pas non plus. Nous avons besoin d’énergie pour alimenter les pompes et les filtres.
Des préoccupations raisonnables ont été exprimées quant aux coûts environnementaux potentiels de la formation à l’IA et de son utilisation croissante. Il convient toutefois de garder à l’esprit la réduction correspondante des coûts.
Les coûts d’inférence, ou les coûts des réponses de l’IA, ont chuté de 99,7 % en deux ans, soit 0,03 % de ce qu’ils étaient auparavant, grâce à des gains d’efficacité tels que des modèles distillés sur du matériel perfectionné.
L’énergie restera-t-elle une préoccupation ? Oui. Mais elle pourrait bien devenir de plus en plus gérable.
Vos données portent-elles le bon maillot de bain ?
Après avoir examiné la manière dont les données sont collectées, nous devons maintenant nous pencher sur la manière dont elles sont traitées une fois qu’elles sont arrivées.
Tout comme les différentes masses d’eau dans les différents pays font l’objet de restrictions variables, il en va de même pour les données. La souveraineté des données est le concept selon lequel les données sont régies par les lois de l’endroit où elles se trouvent.
En poussant un peu plus loin la métaphore de l’eau, nous pouvons penser à un élément de données qui souhaite aller nager. Si une donnée portant un maillot de bain américain, c’est-à-dire adhérant aux normes de gouvernance des données d’un pays, tente d’entrer dans une piscine française, on lui dira fermement qu’elle doit changer de tenue.

Investir dans l’IA souveraine
La protection de la vie privée et la sécurité nationale ne sont plus des préoccupations abstraites – elles déterminent comment et où les données peuvent être stockées, traitées et utilisées, et le rythme des changements s’accélère d’année en année. La souveraineté des données n’est qu’une partie d’un concept de souveraineté plus large, comprenant la souveraineté des services et la souveraineté de l’IA. L’Europe investit 200 milliards d’euros dans l’IA, dont 20 milliards rien que pour les gigafactories de l’IA, des centres d’infrastructure de l’IA à haute capacité.
Récemment, à Paris, Jensen Huang, PDG de NVIDIA, a annoncé un partenariat avec des entreprises françaises, italiennes, polonaises, espagnoles et suédoises afin de fournir des modèles d’IA en grandes langues, ou LLM, adaptés aux langues et aux cultures locales et hébergés sur des infrastructures d’IA régionales.
“Les entreprises investissent dans l’IA comme elles l’ont fait autrefois pour l’électricité et l’internet” – Jensen Huang, cofondateur et PDG de NVIDIA, le25 mai
Aujourd’hui, les règles de souveraineté et les lois sur la protection de la vie privée fragmentent les anciens monolithes en dizaines de bassins :
- Lesdonnées personnelles européennes doivent rester dans les zones réglementées par le GDPR
- Lescontrôles américains à l’exportation limitent les lieux d’hébergement des modèles et des puces d’IA de pointe
- Slack a désactivé les droits d’entraînement des modèles via ses API en mai 2025 ; les développeurs doivent interroger à l’intérieur des murs de Slack.
La souveraineté en matière d’IA signifie contrôler l’ensemble du pipeline de l’IA : posséder ses données, décider de la manière dont les modèles sont formés, exécuter des calculs dans des environnements que l’on gouverne. Il ne s’agit pas seulement de conformité, mais aussi d’autonomie et d’avantage stratégique dans un monde dominé par l’IA.
Une étude de cas sur la gouvernance sécurisée des données d’IA
Voici un exemple tiré de notre expérience où le mouvement sécurisé et régi des données était vital pour permettre le traitement de l’IA.
Une grande institution financière multinationale utilisait Axway MFT pour gérer des flux de transactions de plusieurs billions de dollars sur des millions de fichiers de données agrégés par jour. Elle devait faire transiter les données reçues d’entités externes vers un centre d’échange central, avant de les transmettre à différentes régions distribuées, chacune dotée de sous-systèmes d’IA différents.
Parfois, les données peuvent être déplacées, parfois elles ne le peuvent pas, ou parfois elles ne peuvent être déplacées qu’avec des restrictions. Si vous ne pouvez pas déplacer les données, déplacez l’intelligence. Lorsque les données ne peuvent pas être centralisées – en raison de contraintes de souveraineté, de sécurité ou de conformité – vous devez repenser votre architecture.
Dans certains cas, vous pouvez regrouper vos données en un seul endroit à titre de mesure temporaire ; dans d’autres, vous les distribuez géographiquement en fonction de l’endroit où elles sont autorisées à être traitées. Dans tous les cas, la complexité augmente.

Il existe trois modèles :

C’est là que les approches fédérées entrent en jeu. L’apprentissage fédéré vous permet de former des modèles localement et de partager des informations, et non des données brutes. Les stratégies de stockage fédéré permettent de gérer des ensembles de données distribués tout en respectant les règles de souveraineté.
Enfin, grâce à des technologies telles que Model Context Protocol (MCP), introduites par Anthropic en 2024, les agents d’IA peuvent accéder aux données et aux API de manière abstraite, sans avoir besoin de déplacer les données elles-mêmes. Vous devez gérer intelligemment les flux de données à travers un maillage hybride de systèmes, d’emplacements et de contraintes.
Voir aussi : Pourquoi les protocoles d’IA agentique ne sont pas encore prêts pour le prime time
Dans ce cas, la réplication a été la stratégie choisie. Le client pouvait prendre les données d’un seul pool, des millions de fichiers par jour, et les répliquer vers les lacs de données individuels suivants, en acheminant intelligemment les bonnes données au bon endroit.
Comme l‘explique mon collègue Emmanuel Vergé, l’une des valeurs fondamentales de solutions telles que le transfert de fichiers géré n’est pas le mouvement des fichiers lui-même : il s’agit d’obtenir des données à partir des fichiers et de les intégrer dans les systèmes et les applications qui ont besoin de ces informations. Ce que nous appelons le “MFT intelligent” va au-delà du transfert de fichiers en intégrant les données elles-mêmes dans les systèmes et les applications grâce à des modèles d’intégration sans code.
Pour en savoir plus : [Intégration MFT] Ouvrez votre écosystème d’intégration avec le MFT intelligent
À partir de là, un traitement plus poussé permet de créer des modèles d’IA spécifiques à un type de données. À ce stade, nous pouvons soit
- Ouvrir ces pools avec des API et un serveur MCP pour exposer les données à d’autres, ou
- Exécuter des agents et faire en sorte que la communication d’agent à agent (ou A2A) permette d’établir de nouvelles conversations.
Maintenant, avec l’apprentissage fédéré, ils peuvent prendre ces modèles individuels disparates et renvoyer les connaissances (encore une fois, en envoyant des poids et des paramètres de modèle, des données agrégées et abstraites, mais des données tout de même) vers un modèle centralisé pour une plus grande puissance.
Cinq règles pour une infrastructure d’IA prête pour la souveraineté
Nous avons établi cinq règles pour aider les organisations à préparer leur infrastructure d’IA prête pour la souveraineté.
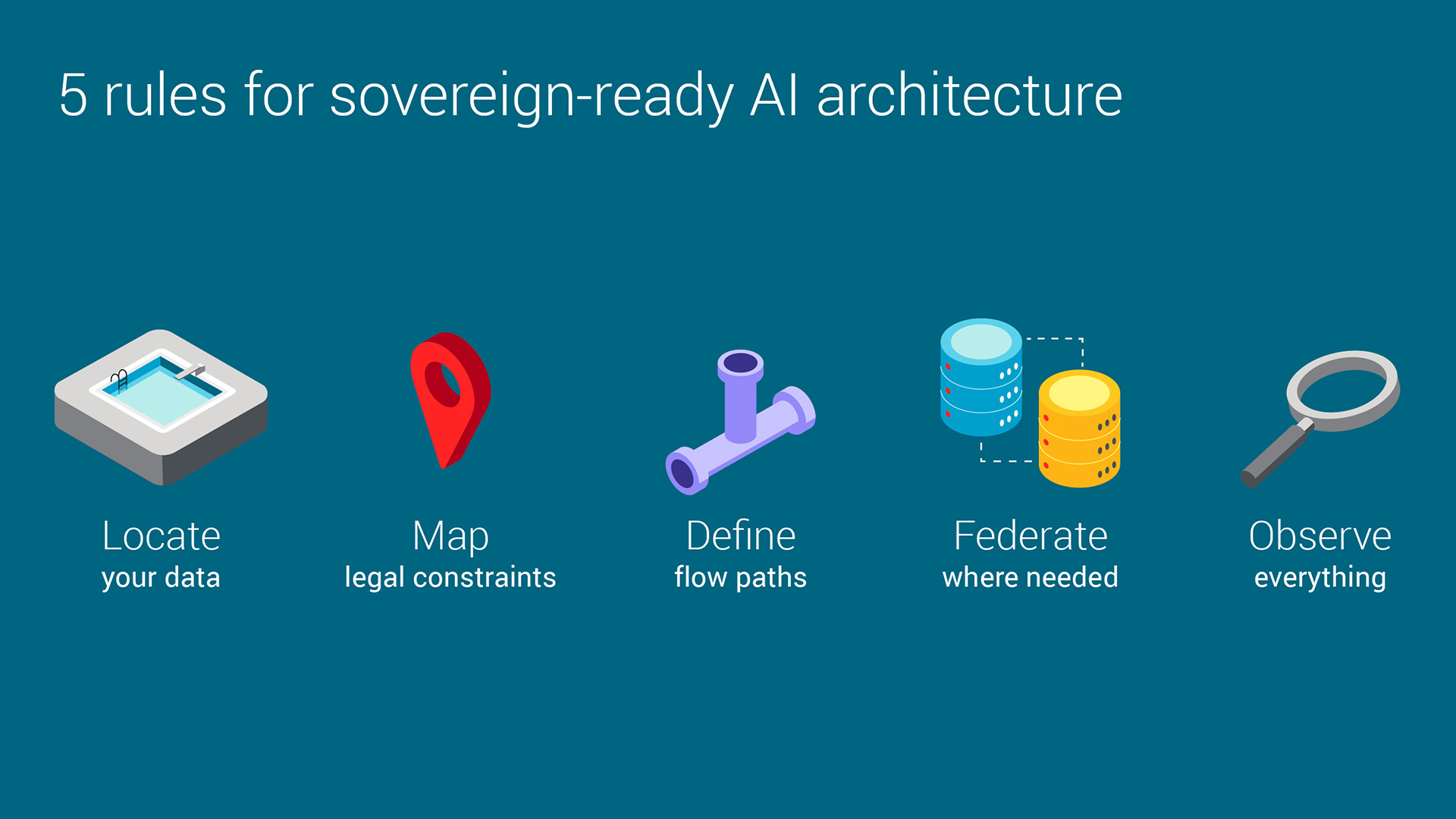
- Localiser: Tout d’abord, localisez l’endroit où résident vos données.
- Cartographier: Ensuite, comprenez les règles qui s’appliquent à ces données. Pouvez-vous les déplacer ? Ou devez-vous les traiter sur place ?
- Définissez: Troisièmement, si vous pouvez les déplacer, créez vos flux en intégrant vos différents services. Les technologies et les déploiements hybrides vous permettent de déplacer les données lorsque c’est nécessaire, tout en vous permettant de cloisonner ou de rapatrier les données qui doivent rester locales.
- Fédérer: Si vous ne pouvez pas les déplacer, envisagez soit de former localement des modèles pour exporter des connaissances si vous devez former une IA mondiale, soit d’exposer les données via des approches MCP afin que des agents d’IA distants puissent interagir avec elles.
- Observer: Enfin, assurez-vous d’avoir une bonne observabilité de votre paysage de données, de comprendre où se trouvent les données à tout moment et d’en contrôler l’accès.
Notre mission est de permettre l’innovation sans sacrifier le contrôle. C’est pourquoi nous avons conçu Amplify AI Gateway pour répondre à cette demande d’intégration sécurisée, conforme et flexible de l’IA, vous permettant d’opérationnaliser l’IA en tant que composant transparent et gouvernable de l’architecture de votre entreprise.
Grâce à des combinaisons comme Amplify Fusion Axway MFT, nous sommes en mesure d’étendre la connectivité de transfert de fichiers en fournissant une intégration sans code pour les données, les applications, les événements et les API.
En traitant les données comme un service public essentiel (approvisionnement, déplacement et gouvernance sécurisés), nous pouvons libérer le potentiel de l’IA tout en répondant aux exigences les plus strictes en matière de souveraineté, de confidentialité et d’énergie.
En savoir plus sur la manière dont Amplify AI Gateway permet une intelligence sécurisée, gouvernée et composable