


This June, I had the honor of delivering a keynote at Nexus Luxembourg 2025. This is Axway’s first time at the conference, now in its second year, which focuses on accelerating AI and innovation in tech. My colleagues Jeroen Delbarre and Hamdi Arous also presented Amplify Fusion, , and we found it an inspiring event featuring many industry leaders.
It is critical to provide data to AI reliably and securely. While many are focusing on the quality of data for AI use and the sovereignty issues at play, I’m seeing scant discussion about the infrastructure and management required, or the how, of getting this quality data to the AI models at scale.
That’s where Axway comes in.
Using the analogy of data as water helps to illustrate the situation in an easy-to-understand way, so let’s dive right into what I like to call “liquid intelligence.”
As water gives us life, data gives life to AI
Water, like data, is everywhere. It flows from one location to another. It’s measured, monitored, and treated to improve quality along the way.
Not long ago, systems had neatly structured data architectures. If you needed to light up a web application, you just turned on a LAMP. Nowadays, our data comes from many more sources and is retransmitted, cached, enriched, and filtered.
From IoT devices to mobile phones, the data we need to inspect does not collect into a single pool of a LAMP server, but into the many puddles, pools, lakes, and oceans of our corporate data estates.
- By age 20, a human has heard 150 million words. GPT-4 has viewed 5 trillion words at birth.
- AI needs data to survive. And it doesn’t just sip—it gulps
What’s more, genAI doesn’t wait until the data is nicely collected in a well-bordered pool. We need to figure out how to get the data from where it is to where it needs to be, in a way that is secure, scalable, and efficient.
Just like the water supply in any city, protecting the integrity and safety of data is not just about where your data resides—it’s about how it moves. One of today’s challenges is managing that flow: consolidating some data, splitting or routing other data across multiple, sometimes federated, pools.
To do that effectively, you need to know exactly where your data is now, where it needs to go, and how to move it securely and with proper governance.
Without trusted, well-governed data in motion, your AI can’t run.
Plumbing is not necessarily the flashiest analogy for the heady world of AI, but it is very apt. The infrastructure required is much like the aqueduct systems, without which Rome could not have built baths, forums, or a future.
Data gravity used to pull everything together. Now, governance pulls it apart
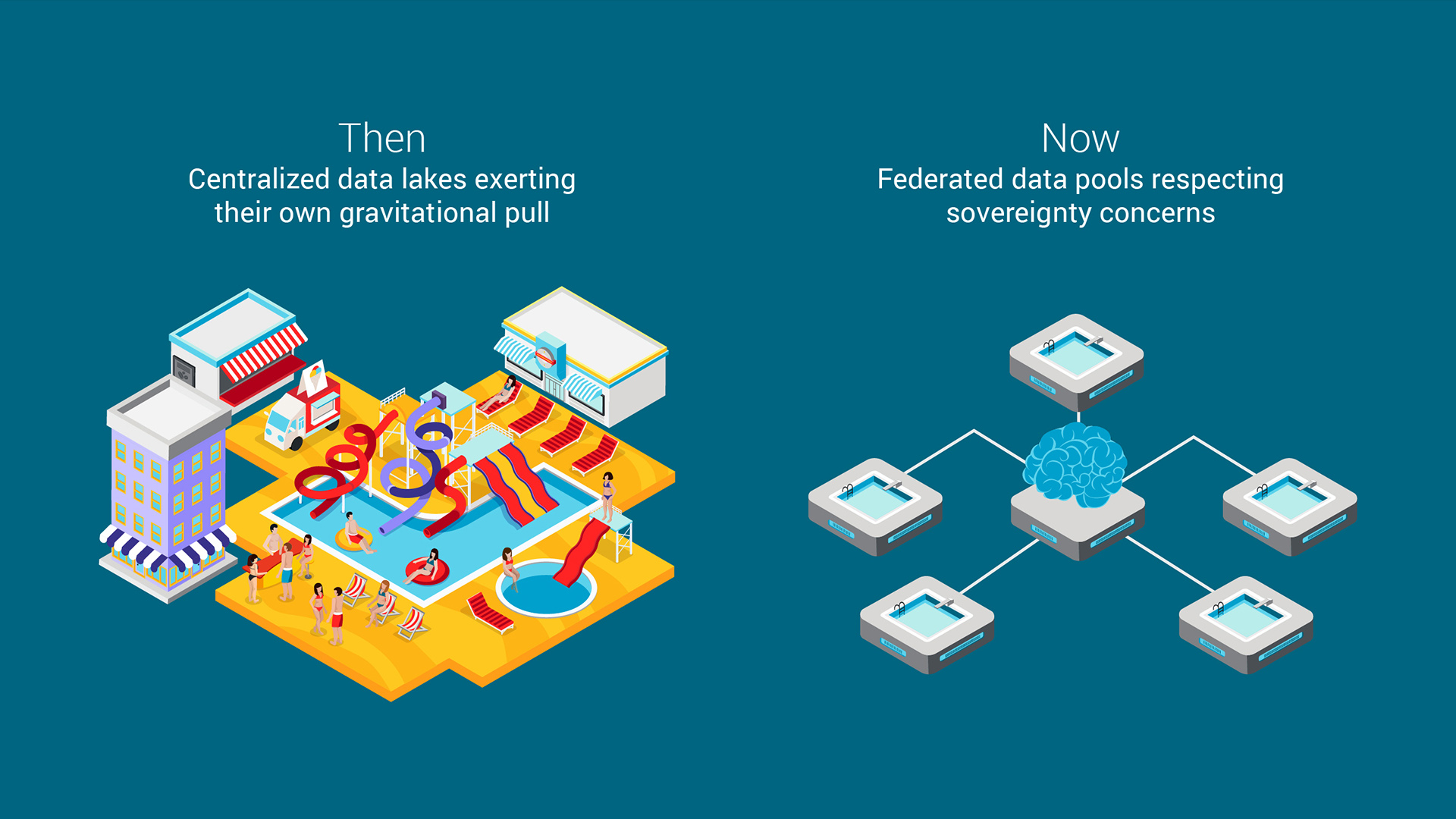
Centralized data lakes
In the past, organizations aimed to bring all their data into one massive, centralized repository—a “data lake.” The sheer size and value of this data created a gravitational pull: applications, services, and analytics tools clustered around it, much like shops and restaurants gather around a popular theme park. This effect is known as data gravity—the more data you have in one place, the more things want to come to it.
Federated data pools
Today, that centralization model is breaking down. Due to data governance, privacy laws, and sovereignty concerns, data often cannot be moved or pooled together across borders or systems. Instead of one giant lake, we now manage many distributed pools—each governed by its own rules. Rather than moving all data to one place, we build systems that let intelligence flow between them, while keeping the data where it is legally and/or ethically determined to belong.
Energy concerns
We would be remiss if we didn’t touch on the subject of energy. Just as water cannot move through pipes in today’s cities by gravity alone, neither can data. We need energy to power pumps and filters.
Reasonable concerns have been raised about the potential environmental costs of AI training and its rising use. It is also worthwhile keeping in perspective, however, the corresponding reduction in costs.
Inference costs, or the costs of AI responses, have dropped by 99.7% in 2 years, or they are .03% of what they used to be, driven by efficiencies such as distilled models on refined hardware.
Will energy continue to be a concern? Yes. But it is one that may well become increasingly manageable.
Is your data wearing the right swimsuit?
Having considered how the data is collected, we now must consider how the data is treated once it arrives.
Just as different bodies of water in different countries face varying restrictions, so too does data. Data sovereignty is the concept that data is governed by the laws of the location in which it resides.
Leaning a little further into the water metaphor, we can think of a piece of data that wishes to go swimming. Should a piece of data wearing an American swimsuit, i.e., adhering to one country’s data governance norms, try and enter a French pool, it will be firmly told it needs to change outfits.

Investing in sovereign AI
Privacy and national security are no longer abstract concerns—they’re driving how and where data can be stored, processed, and used, and the pace of change increases yearly. Data sovereignty is just part of a larger sovereignty concept, including service sovereignty and AI sovereignty. Europe is investing 200 billion EUR in AI, including 20 billion alone for AI gigafactories, high-capacity AI infrastructure hubs.
Just recently in Paris, NVIDIA CEO Jensen Huang announced a partnership with firms in France, Italy, Poland, Spain, and Sweden to deliver local sovereign large language AI models, or LLMs, tailored to local languages and culture, hosted on regional AI infrastructure.
Companies are investing in AI like they once did for electricity and Internet” – NVIDIA Co-Founder & CEO Jensen Huang, May 25th
Today, sovereignty rules and privacy statutes fragment previous monoliths into dozens of pools:
- European personal data must remain in regulated zones under GDPR
- U.S. export controls restrict where cutting-edge AI models and chips may be hosted
- Slack switched off model-training rights via its APIs in May 2025; developers must query inside Slack’s walls.
AI sovereignty means controlling the full AI pipeline: own your data, decide how models are trained, run compute in environments you govern. It’s not just about compliance—it’s about autonomy and strategic advantage in an AI-driven world.
See also Data governance in action: Axway’s leadership on privacy and security
A case study in secure AI data governance
Here’s an example from our experience where the safe, governed movement of data was vital to the enablement of AI processing.
A large multinational financial institution was using Axway MFT to handle trillions of dollars in transaction flows across millions of aggregated data files per day. They needed to shuttle data received from external entities into a central clearinghouse, to then be forwarded to different distributed regions – each with different AI subsystems.
Sometimes data can be moved, sometimes it can’t, or sometimes it can only be moved with restrictions. If you can’t move the data, then move the intelligence. When data can’t be centralized—due to sovereignty, security, or compliance constraints— you need to rethink your architecture.
In some cases, you might pool your data in one place as a temporary measure; in others, you distribute it geographically based on where it’s allowed to be processed. Either way, complexity increases.

Three models exist:

That’s where federated approaches come in. Federated learning lets you train models locally and share insights, not raw data. Federated storage strategies help manage distributed datasets while respecting sovereignty rules.
And with technologies like Model Context Protocol (MCP), introduced by Anthropic in 2024, AI agents can access data and APIs abstractly, without needing to relocate the data itself. You need to manage data flows intelligently across a hybrid mesh of systems, locations, and constraints.
See also : Why Agentic AI protocols aren’t ready for prime time yet
In this case, replication was the chosen strategy. The customer could take the data from a single pool, millions of files per day, and replicate it to subsequent individual data lakes, intelligently routing the correct data to the correct location.
As my colleague Emmanuel Vergé discusses here; one of the core values of solutions like managed file transfer isn’t the movement of files itself: it’s getting data from the files and integrating it into the systems and applications that need the information. What we call “intelligent MFT” goes beyond file transfer by integrating the data itself into systems and applications through no-code integration patterns.
Read more : [MFT Integration] Open Up Your Integration Ecosystem with Intelligent MFT
From there, further processing enables type-specific AI models. At this point, we can either:
- Front these pools with APIs and an MCP server to expose the data to others, or
- Run agents and have agent-to-agent communication (or A2A) broker new conversations.
Now, with federated learning, they can take these disparate individual models and return the knowledge back again (again, shipping model weights and parameters, aggregated, abstracted data, but data all the same) back to a centralized model for greater power.
Five rules for sovereign-ready AI infrastructure
We’ve come up with 5 rules to help organizations get ready for their sovereign-ready AI infrastructure.
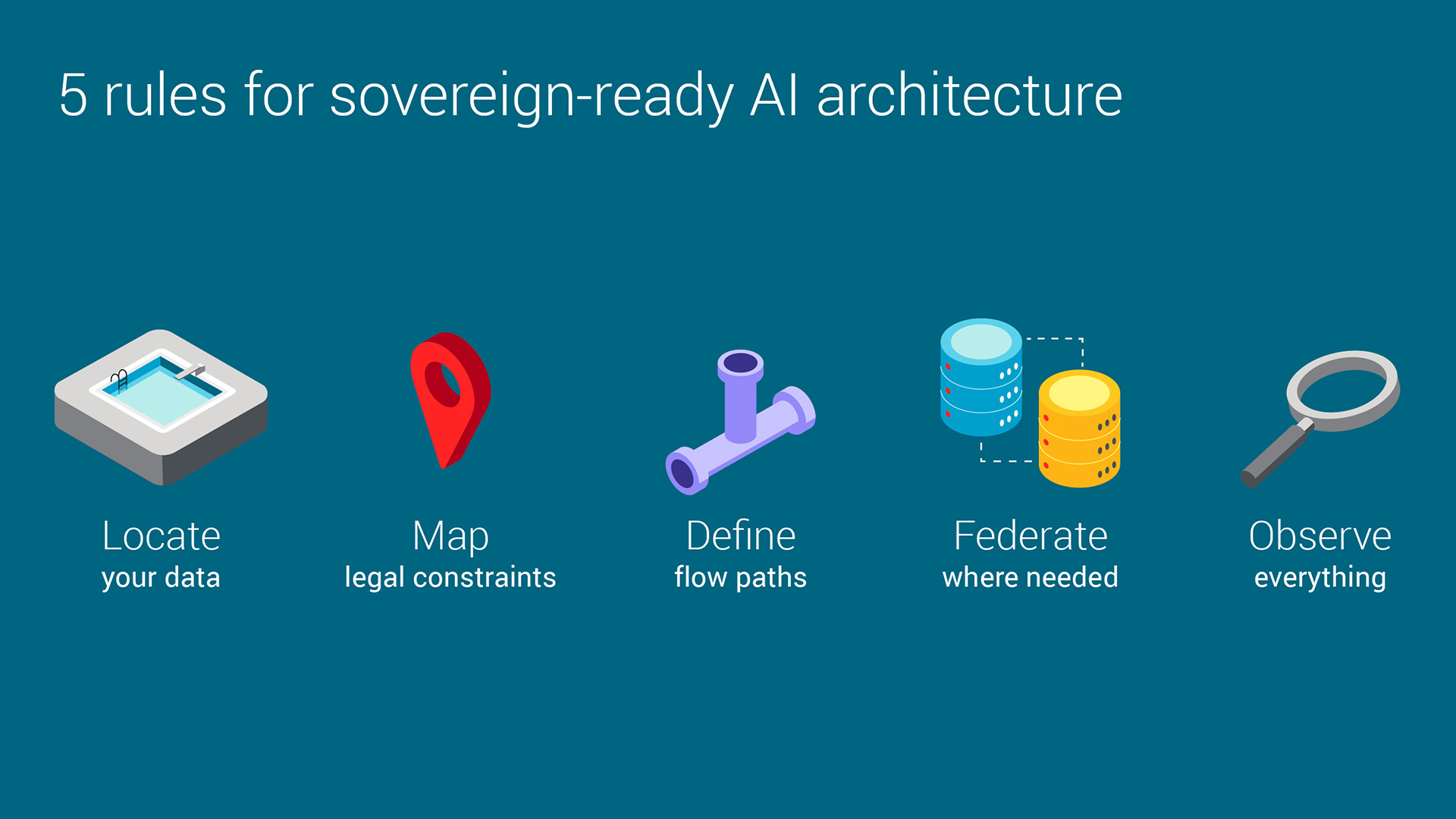
- Locate: First, locate where your data resides.
- Map: Second, understand the rules that apply to that data. Can you move it? Or do you have to process it in place?
- Define: Third, if you can move it, create your flows, integrating your various services. Hybrid technologies and deployments allow you to shuttle data around where appropriate, while allowing you to silo or repatriate data that needs to stay local.
- Federate: If you can’t move it, consider either locally training models to export knowledge if you need to train a global AI, or exposing the data via MCP approaches so that remote AI agents can interact with it.
- Observe: Finally, ensure that you have good observability into your data landscape, understanding where the data is at any moment, and controlling access.
Our mission is to enable innovation without sacrificing control. It’s why we designe Amplify AI Gateway to answer this demand for secure, compliant, and flexible AI integration, letting you operationalize AI as a transparent, governable component of your enterprise architecture.
Through combinations like Amplify Fusion and Axway MFT, we’re able to expand file transfer connectivity by providing no-code integration for data, applications, events, and APIs.
By treating data like a critical utility—safely sourced, moved, and governed—we can unlock AI’s potential while meeting the toughest sovereignty, privacy, and energy demands.
Learn more about how Amplify AI Gateway enables secure, governed, composable intelligence