

Does getting a high available Rule Engine and gaining money at the same time seem contradictory? We will demonstrate that using new technologies is becoming the new norm.
The old way
After more than 30 years, Rule Engine is a mature product that runs accounting for some of the biggest financial companies in the world. As it is a critical system, our customers need to ensure that the service is always available to respond to business constraints.
Not so long time ago, the main strategy to achieve that was to have a production server in parallel processing your accounting, and a backup server running the same configuration and ready to take the hand in case of failure of the first one.
So, you have a piece of expensive hardware doing absolutely nothing 99% of the time, and you still need to invest to make sure that it is up to date and do expensive regular disaster recovery tests periodically.
In addition to that, should a real crash happen, the experience proves that you usually need several hours to put your back up online and multiple manual actions to relaunch your process.
If we summarize at a high level:
| Nominal time to process 50 files | In case of disaster | Manual action | Cost | |
| Old way | 1 Hour | + 4-10 hours | Yes | $$$$$$ |
In this first article, we’ll see how the technology has evolved allowing you to achieve Zero Downtime on Rule Engine and to reduce your cost at the same time.
Here comes the Cloud
The first main revolution that comes around is the Cloud which allows you to get rid of your old server. If we take the example of AWS (that is used for Axway Cloud). You can have your Rule Engine running on an EC2 instance in a matter of hours for a fraction of the cost you will need on-premises.
Creating a new environment is a matter of minutes once you automatize everything. Moreover, by using AWS AMI, you can have a backup of your environment with all your rules up to date. Hence, you don’t need any Backup environment, as you can create a new production environment in a different availability zone very quickly in case of failure of your main production environment.
For example, using an auto-scaling group, we can automatically detect an unhealthy instance and relaunch a new one from the AMI store to restore full capacity.
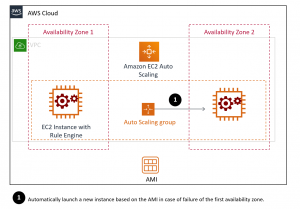
So, with the Cloud, you divide your cost by half, your downtime is still in the order of a few hours because you still need manual actions to relaunch the files that were processing during the outage.
| Nominal time to process 50 files | In case of disaster | Manual action | Cost | |
| The cloud way | 1 Hour | + 1-2 hours | Yes | $$$ |
Moreover, you have to maintain the configuration on your AMI up to date, which means creating a new one, each time to release a configuration change.
To summarize, you can achieve big progress in terms of cost and time to recover, but we are still far away from our Zero Downtime objective and we can do better than that.
In our next article, we will explore how to go deeper and target a complete high availability environment, still going further on the cost reduction side.
Discover how to move to the Cloud with AI Suite on Docker.
========================================================
Version française
Modernisez votre infrastructure AI Suite pour atteindre la haute disponibilité (partie 1)
Est-ce qu’il semble contradictoire d’avoir un Rule Engine en haute disponibilité et gagner de l’argent en même temps ? Nous allons démontrer qu’en utilisant les nouvelles technologies cela devient la nouvelle norme.
À l’ancienne
Depuis plus de 30 ans, Rule Engine est devenu un produit mature qui gère la comptabilité pour certaines des plus grandes compagnies financières internationales. Il est, de fait, un système critique pour nos clients et ils ont besoin de s’assurer que la production est toujours disponible pour répondre aux contraintes du métier.
Il n’y a encore pas si longtemps que cela, la principale stratégie pour atteindre la haute disponibilité était d’avoir deux serveurs en parallèle avec Rule Engine, un premier de production qui traite la comptabilité, et un second de backup avec la même configuration, et prêt à prendre le relais en cas de défaillance du premier.
Donc, vous avez une machine physique qui coûte un bras et qui ne fait rien, presque 99% du temps. De plus vous devez continuer d’investir pour la garder à jour et faire périodiquement de coûteux tests de reprise après sinistre.
Enfin, l’expérience montre que quand un incident de production arrive vraiment, il faut quand même plusieurs heures pour remettre le backup en ligne et relancer manuellement tous les traitements qui ont été interrompus.
Si on schématise à haut niveau :
| Temps nominal pour traiter 50 fichiers | En cas de désastre | Actions manuelles | Coût | |
| À l’ancienne | 1 Heure | + 4-10 Heures | Oui | €€€€€€ |
Dans ce premier article, nous allons voir comment l’évolution des nouvelles technologies permet de viser à n’avoir aucun temps d’arrêt sur Rule Engine et de réduire les coûts en même temps.
Voici venir le Cloud
L’arrivée du Cloud a été la principale révolution qui a permis de se débarrasser de ces anciens serveurs. Si nous prenons l’exemple de AWS (qui est utilisé pour le Cloud Axway), vous pouvez avoir votre Rule Engine qui tourne sur une instance EC2 en quelques heures et pour une fraction du coût qui serait nécessaire pour une installation sur site client.
Une fois que tout est automatisé, il est possible de créer un nouvel environnement en seulement quelques minutes. De plus, en utilisant AWS AMI, vous pouvez créer une sauvegarde de votre environnement avec toute votre configuration à jour. Ainsi vous n’avez plus besoin d’un environnement de backup, puisque vous pouvez créer un nouveau serveur de production dans une zone de disponibilité différente très rapidement en cas d’incident sur votre production principale.
Par exemple, en utilisant un auto-scaling group, il est possible de détecter automatiquement une instance en mauvaise santé et en relancer une nouvelle depuis votre base d’AMI afin de restaurer une capacité de production optimum.
Avec le Cloud, vous avez divisé votre coût de moitié, mais votre temps d’indisponibilité est toujours de plusieurs heures, car il est nécessaire de réaliser plusieurs actions manuelles afin de relancer les fichiers qui étaient en train d’être traités durant l’incident.
| Temps nominal pour traiter 50 fichiers | En cas de désastre | Actions manuelles | Coût | |
| Dans le Cloud | 1 Heure | + 1-2 Heures | Oui | €€€ |
De plus, il faut maintenir la configuration de votre AMI, ce qui signifie qu’il faut en créer une nouvelle à chaque fois que la configuration change.
En synthèse, il est possible d’arriver à de gros progrès aussi bien en termes de coût que de temps de reprise, mais on est encore loin de notre objectif de n’avoir aucun temps de reprise après sinistre, et nous pouvons faire mieux que cela.
Dans notre prochain article, nous allons explorer en profondeur comment atteindre un environnement en haute disponibilité, tout en continuant de réduire les coûts.
Découvrez les avantages de la migration vers le cloud avec Docker.