

Getting a high available Rule Engine environment and gaining money at the same time seem contradictory? We will demonstrate that using new technologies is becoming the new norm.
Rule Engine environment: Summary of Part 1
Our goal is to look for a way to achieve at the same time high availability and cost reduction for the Rule Engine environment.
We have seen in Part 1 how the Cloud helps to reduce the costs, but miss the point on our Zero Downtime objective. Let’s dig in more.
Transform your batch into a service
For several years, Axway proposes the Rule Server module which allows you to transform your traditional Rule Engine into a service that can consume files automatically or that can be called using REST API.
Its main advantages are the ability to:
- Manage a pool of Rule Engine to process a file in parallel
- Modulization of your multi-stage process
- Centrally manage your configuration using the AI Suite Portal UI, your process is always up to date
- Ensure high availability of your process
Let’s talk a little more about the last point.
When managing a multi-step process (for example, three Rule Engine processing in cascades), Rule Server will manage each step independently storing the logical result in an Event Queue inside Rule Server Database.
Hence, you can have several Rule Engine processes listening to your central Event queue, and each one will consume an Event as soon as there is some availability in its pool of processing. So, it’s easy to have two Rules Servers running in a high availability mode.
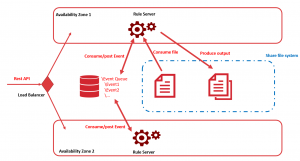
It is the solution we chose to run our own AI Suite Cloud. Each Rule Server is in a different availability zone and is always up, so if one AWS data center crashes, we always have the other that is working on consuming Event retrieving files from the shared file system.
Moreover, the system will detect that one Rule Server is not responding anymore and the process in progress will be reposted again in the queue list, which means that no manual action is required in case of an incident.
Finally, we use AWS RDS to have a high availability database, and AWS EFS to ensure the high availability of our data.
So, if we come back to the summary of our previous blog:
| Nominal time to process 50 files | In case of disaster | Manual action | Cost | |
| Cloud + Rule Server | 30 Minutes | + 30 Minutes | No | $$ |
To summarize, you have two Rule Engines always working in parallel and balancing the load, so your processing time is cut in half. Moreover, if one of them crashes, the other one will be able to retrieve all the load to complete the process automatically, and of course, you can couple this with an auto-scaling group to reduce the time of recovery even further.
As you can see, we have achieved our Zero Downtime objective, having a service always available, with no manual action; but actually, we can still do a little more on the cost side.
Put your application in a container
Once you have transformed your traditional Rule Engine into a service, it is very easy to move to Docker and Kubernetes using the image provided by Axway.
Docker allows you to transform your application into a container that can run anywhere, and Kubernetes will allow you to create a cluster of working nodes on which you can run your dockers.
The advantage is that you can create a cluster that will shelter many Docker applications alongside your Rule Engine processes. Each application sharing the same physical resources, but being segregated on the logical and network-level with the capability of Kubernetes.
Moreover, since your cluster is divided across several availability zones, if one zone comes down, Kubernetes will be able to provision automatically a new node in the remaining one and relaunch your docker to come back automatically to full-processing capability within a minute and without any human interactions, thus restoring your production to 100% efficiency.
| Nominal time to process 50 files | In case of disaster | Manual action | Cost | |
| Cloud + Rule Server + Docker | 30 Minutes | + 5-10 Minutes | No | $ |
It allows you to decrease your cost even further, because you don’t have to book virtual machines specifically for your Rule Engine, but you manage your resources at the company-level, taking into account the computing power you need globally.
Conclusion
As you can see, with the new technology you can make your critical Rule Engine process in high availability, thus reducing the risk to your business, and reducing your cost at the same time.
| Nominal time to process 50 files | In case of disaster | Manual action | Cost | |
| Old way | 1 Hours | + 4-10 hours | Yes | $$$$$$ |
| The cloud way | 1 Hours | + 1-2 hours | Yes | $$$ |
| Cloud + Rule Server | 30 Minutes | + 30 Minutes | No | $$ |
| Cloud + Rule Server + Docker | 30 Minutes | + 5-10 Minutes | No | $ |
Moreover, you are not obliged to follow the order of this article, and you can start by running Docker on-premise, and then moving to the cloud, etc.
Finally, we have demonstrated that you must not think anymore about Rule Engine as an old batch with all the constraints it comes with, but you should think about it as a service that can be consumed and scaled in your SI to answer your business-critical need.
Moreover, moving to such technologies will have an impact on your specific orchestration and batch processing, but it has zero impacts on the accounting rule configure in the Rule Engine, so there is no functional issue to migrate, and we at Axway can help you with that.
To better understand the possibility of Docker, I recommend reading about Demystifying Containers, Cloud, and Bare Metal. Further, everything we describe on AWS is possible on any other major Cloud provider with their functionalities.
Version française
Modernisez votre infrastructure AI Suite pour atteindre la haute disponibilité (partie 2)
Notre objectif est de trouver un moyen de mettre Rule Engine en haute disponibilité tout en réduisant les coûts.
Nous avons vu dans la première partie, comment le cloud peut aider à réduire les coûts, mais ne permet pas d’atteindre notre objectif de n’avoir aucun temps d’arrêt. Allons plus loin.
Transformer votre batch en mode service
Depuis plusieurs années, Axway propose le module Rule Server qui permet de transformer un Rule Engine traditionnel en un service qui consomme des fichiers automatiquement ou qui peut être piloté par des API REST.
Ses principaux avantages sont:
- Gérer un pool de Rule Engine afin de traiter des fichiers en parallèle
- Les traitements en plusieurs étapes sont modularisés
- La configuration est gérée de façon centralisée depuis l’IHM d’AI Suite Portal. Vos traitements ont toujours la dernière mise à jour.
- Votre processus est en haute disponibilité
Voyons un peu plus en détails le dernier point.
Quand votre processus est composé de plusieurs étapes (par exemple, trois traitements Rule Engine à la suite), Rule Server va gérer chaque étape de façon indépendante, en stockant le résultat logique de chaque étape dans une queue d’événements à l’intérieur de la base de données du Rule Server.
Du coup, il est possible d’avoir plusieurs Rule Server qui écoutent cette queue d’événements centralisée et chacun va consommer des événements dès qu’il a de la disponibilité dans son pool de traitement. Il est donc facile d’avoir deux Rule Server fonctionnant en haute disponibilité.
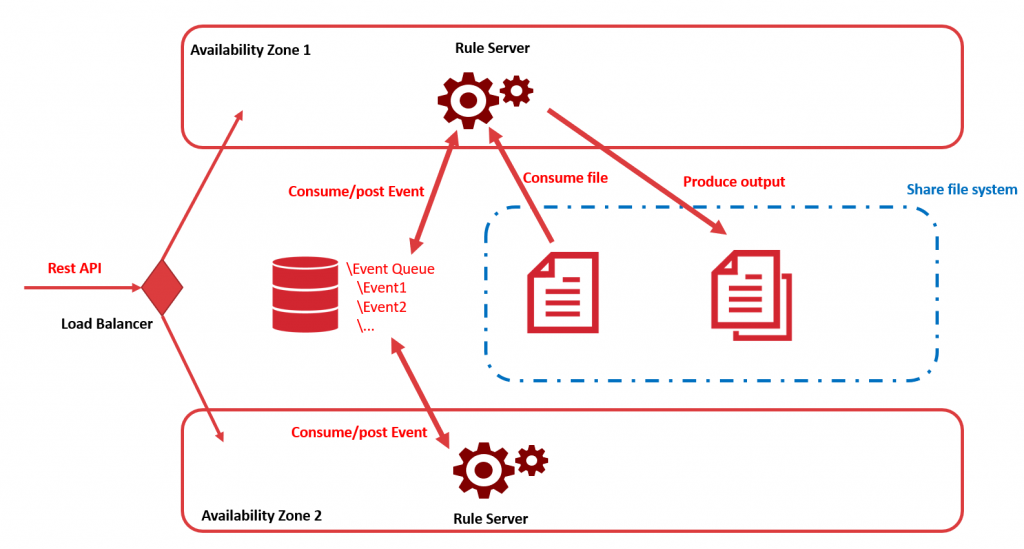
C’est la solution que nous avons choisie pour notre propre cloud AI Suite . Chaque Rule Server est dans une différente zone de disponibilité et fonctionne tout le temps, ainsi si un datacenter d’AWS à un sinistre, le deuxième est toujours opérationnel et peut consommer des événements pour traiter des fichiers depuis le file system partagé.
De plus, le système va détecter si un Rule Server ne répond plus, afin que les traitements en cours soient remis dans la queue automatiquement. Il n’y a donc aucune action manuelle nécessaire en cas de désastre.
Finalement, nous utilisons le service AWS RDS pour avoir nos bases de données en haute disponibilité et AWS EFS pour la haute disponibilité des fichiers.
Du coup, si on revient à la synthèse de notre précédent blog
| Temps nominal pour traiter 50 fichiers | En cas de désastre | Actions manuelles | Coût | |
| Cloud + Rule Server | 30 Minutes | + 30 Minutes | Non | €€ |
Pour synthétiser, nous avons deux Rule Engine qui travaillent en collaboration pour se partager la charge, ce qui implique que le temps de traitement est divisé par deux. De plus, si un des deux se crash, le deuxième va automatiquement récupérer la charge pour compléter les traitements et bien évidement pour pouvoir coupler ça avec des autoscaling group pour réduire le temps de reprise encore plus.
Comme vous pouvez le voir, nous avons atteint notre objectif de n’avoir aucun temps d’arrêt, avec aucune action en cas de sinistre; mais nous pouvons quand améliorer les coûts.
Mettez votre application dans un container
Une fois que vous avez transformé votre Rule Engine traditionnel en un service, il est très facile de passer à Docker et Kubernetes en utilisant les images fournies par Axway.
Docker permet de transformer votre application en un container qui peut tourner n’importe où et kubernetes permet de créer des clusters dans lesquels les containers docker peuvent tourner et répartir la charge.
L’avantage est que vous pouvez créer un cluster qui va abriter plusieurs applications Docker en même temps que vos traitements Rule Engine. Chaque application va se partager les ressources physiques du cluster, mais est ségréguée au niveau logique et réseau par Kubernetes.
De plus votre cluster va s’étendre sur plusieurs zones de disponibilités, et si une zone tombe, kubernetes est capable de provisionner automatiquement de nouveaux nœuds dans celles qui restent et relancer les containers pour restaurer une pleine capacité de production en seulement quelques minutes et cela sans aucune action humaine.
| Temps nominal pour traiter 50 fichiers | En cas de désastre | Actions manuelles | Coût | |
| Cloud + Rule Server + Docker | 30 Minutes | + 5-10 Minutes | Non | € |
Cela permet donc de réduire encore les coûts, parce que désormais vous ne réservez plus des machines virtuelles pour un traitement spécifique, mais vous gérez vos ressources au niveau de la société, en prenant en compte votre besoin de ressources au niveau global.
Si vous voulez mieux comprendre les possibilités de Docker, je vous recommande de lire cet article Demystifying Containers, Cloud, and Bare Metal.
Conclusion
Comme nous venons de voir, avec les nouvelles technologies, vous pouvez mettre vos traitements Rule Engine critiques en haute disponibilité, et du coup de réduire les risques pour votre business, tout en réduisant les coûts.
| Temps nominal pour traiter 50 fichiers | En cas de désastre | Actions manuelles | Coût | |
| A l’ancienne | 1 Heure | + 4-10 heure | Oui | €€€€€€ |
| Cloud | 1 Heure | + 1-2 heure | Oui | €€€ |
| Cloud + Rule Server | 30 Minutes | + 30 Minutes | Non | €€ |
| Cloud + Rule Server + Docker | 30 Minutes | + 5-10 Minutes | Non | $ |
Vous n’êtes pas obligé de suivre l’ordre de cet article, vous pouvez commencer par Docker sur site client, et ensuite aller vers le cloud, etc..
Finalement, nous avons démontré qu’il ne faut plus penser à Rule Engine comme un traitement en mode batch avec toutes les contraintes que cela apporte, mais qu’il faut réfléchir en mode service, qui peut être consommé et grandir au sein de votre SI en toute liberté pour répondre au besoin du business.
Aller vers de telles technologies aura un impact sur votre orchestration spécifique et votre traitement en mode batch, mais cela n’a aucun impact sur les règles comptables à l’intérieur de Rule Engine, il n’y a donc aucun problème fonctionnel à migrer et nous, Axway, pouvons vous aider à faire cela.
Bien évidemment, tout ce que nous décrivons sur AWS est possible sur tous les principaux fournisseurs de Cloud avec leurs propres services.