



The purpose of this post is to highlight the different Kafka capabilities which explain its wide adoption in the industry and also attracted the AMPLIFY™ Streams R&D team to the point of making it a central component that supports Streams (v2) event-driven architecture.
If data is the blood, Kafka is the vein…
What is Apache Kafka?
Apache Kafka is an open-source distributed streaming platform that enables data to be transferred at high throughput with low latency. Kafka was originally conceived at LinkedIn and open-sourced in 2011.
At its core, Kafka is a Pub/Sub system with many desirable properties, such as horizontal scalability and fault tolerance. Over the years, Kafka has become a central platform for managing streaming data in organizations and is now adopted by large companies such as Twitter, Uber, Netflix, Dropbox and Goldman Sachs.
Confluent, the company behind the enterprise edition, claims production deployments for six of the top 10 travel companies, seven of the top 10 global banks, eight of the top 10 insurance companies, and nine of the top 10 US telecom companies, read TechRepublic for more information.
We are also seeing growing interest and adoption of Kafka within Axway in various components of the Axway AMPLIFY platform such as the Edge Agent, Axway Decision Insight and SecureTransport.
Kafka capabilities as a backbone underpinning microservices communication
Microservices have communicated with each other in different ways since their inception. Either by direct calls between services such as HTTP Rest APIs or by intermediate message queues such as RabbitMQ to remove the communication and routing decisions burden from the individual services.
But what makes Apache Kafka different?
Like other message brokers systems, Kafka facilitates the asynchronous data exchange between microservices, applications and servers.
But unlike most message brokers which rely on a “smart producer—dumb consumer” model, Kafka has very low overhead because it does not track consumer behavior and delete messages that have been read. Instead, Kafka retains all messages in logs for a set amount of time and makes the consumer responsible for tracking which messages have been read; hence why this model is referred to as “dumb producer/smart consumer.”
At its essence, Kafka provides a durable message store like a log that stores streams of records in categories called topics. Its design makes it, in fact, closer to a distributed file system or a database commit log than traditional message brokers.
This alternative design makes Kafka well suited for high-volume publish-subscribe messages and streams, meant to be durable, fast, and scalable on which it is easy to build a scalable microservice architecture on top of.
This ability helped us break down our monolith into an event-driven microservice architecture that relies entirely on an asynchronous exchange that eases both vertical and horizontal scaling.
Kafka as a “firehose ingestor”
The way messages are stored within Kafka (Append only/Write-Ahead Logs) and the fact that producers are fully decoupled from consumers makes Kafka a good choice for use cases where publishers have to deliver messages at a very high volume and speed while allowing several consumers to read messages at their own pace.

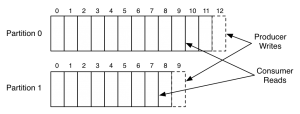
This capability is of interest to the financial sector in which Streams is already present. For example, Bloomberg uses Kafka to handle millions of market movements per second with ultra-low latency, as well as performing complex analytics like outlier detection, source confidence evaluation (scoring), arbitrage detection and other financial-related processing.
Kafka as a backbone underpinning stream processing pipeline
The demand for stream processing is increasing every day and can be explained by two main reasons:
- First, we’ve entered the era of the data economy, the volume of data a company must process daily explodes—data has become the blood of our organizations and has a central role in many business models.
- Second, it becomes essential for organizations to process this constantly growing data at faster rates so that they can react to changing business conditions in (near) real-time.
In stream processing, the data is generated continuously by different sources and processed incrementally vs. long-batch processing based on older big data processing engines such as Hadoop/Hive.
In the context of real-time processing, one important piece of the puzzle is having the ability to ingest large flow of continuous data streams (a.k.a. firehose) from different sources as well as making the data flow between the different stages involved in the processing chain.
Finally, results of this processing must then be conveyed to the appropriate downstream applications to be consumed—either by humans (notification, real-time dashboards…). Or by systems of record (e.g. a relational database or data lake) for further analysis.
Kafka has more added some stream processing capabilities to its own thanks to Kafka Streams.
Kafka Streams is an extension of the Kafka core that allows an application developer to write continuous queries, transformations, event-triggered alerts, and similar functions without requiring a dedicated stream processing framework such as Apache Spark, Flink, Storm or Samza.
Here’s the interesting story of Kafka adoption by the Twitter Engineering team which highlights this use case.
At Streams, we seek to leverage Kafka Streams to compute, in near real-time, the incremental updates (patches) that we must send to subscribers each time a new snapshot of data is published. Discover what you need to know about AMPLIFY Streams.
As we can see, Kafka is now evolving from a pure messaging system (“vein”) to a full-fledged data streaming platform making it a potential “brain” for stream processing pipelines.
We hope this sharing of experience will be useful in your journey to event-driven architecture.
Five strategies for making the switch from monolith to microservices.