

Internet-scale services are built of Microservices. While we are getting ready to approach our customers with Service Mesh, I thought it’s important to get a feel of building services using our own tools. I used .Net and Service Fabric in the past for building scalable services. In this post, I want to share my experience building stateless service using an API Builder Standalone.
The Design approach – Stateful or Stateless
Applications built using Microservices have stateful and stateless services. Stateful services are easy to develop. Each service holds context information that makes it fast and efficient in processing. These types of services increase persistence and stickiness.
Stateless design is considered as a best practice that allows applications to scale-out easily. Stateless services work fine but real-life applications have states, Examples: user info, wizard data, shopping carts, etc. So, when designing stateless services, we don’t avoid states but rather push them to a lower tier.
If not implemented correctly, stateless services can be expensive! Horizontally scaled stateless services will carry out the same tasks repeatedly.
Let’s say, we have a service that queries data from the database and manipulates it before sending a response. All steps will be executed each time the service is called and even for identical requests. This approach increases latency and resource consumption. Keeping frequently accessed data in some distributed in-memory data stores and making it available to the services resolves this issue.
Stateless architecture using API Builder Standalone and Hazelcast
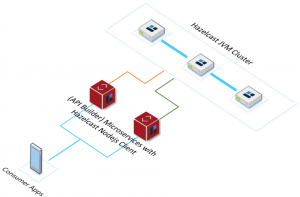
API Builder Standalone
As shown above, API Builder apps use Hazelcast distributed data structures (Imap, in this example) for storing frequently accessed data. API apps and Hazelcast cluster can scale-out independently. There could be an RDBMS/Data-tier behind the Hazelcast cluster.
Why Hazelcast?
- It’s easy to set up, scale and run
- It’s Fast
- Supports multiple data structures such as Maps, Lists, Queues, Topics, Cache, Set, Queries, etc.
- Built-in management center with dashboard views
Example implementation
- Download and run the Hazelcast Node
- Create API Builder Standalone app
- Add Hazelcast Nodejs client to your project

- Create Flow node in your project
- I created READ and WRITE methods to work with Hazelcast nodes. I am using Map data structure like a “cache”
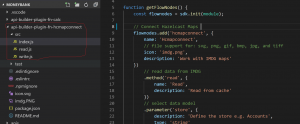
Add a client config file with user credentials and cluster information. It is also possible to set these values as declarative configuration or programmatically.

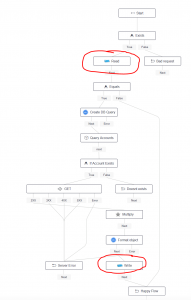
6. Example flow:
In this example, flow is designed to query account balance (in SGD) from the database then it calls a Forex service and returns the account balance in USD. Performance increased significantly when I used Hazelcast flow nodes (step 5) to store and fetch resultset.
7. Observations
Single request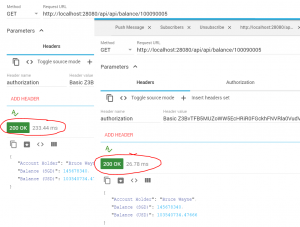
Performance test results
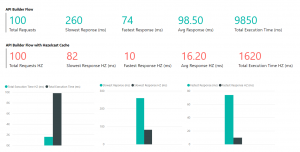
Hazelcast Map usage dashboard
Learn how DevOps and microservices help companies innovate faster.