

I spend a lot of my time thinking about MFT and its application in different sizes of businesses and different industries. Thrilling, I know! It is business 101 that we segment markets into small, mid-tier, and enterprise – and we expect that values, outcomes, and capabilities are associated with each, in nice little boxes.
However, MFT is a strange beast. It fundamentally underpins IT and business operations, often critically relied upon – irrespective of the size or segmentation of the business. It is because of this I often think of MFT users less in terms of the size of their business and more by the size of their requirements. Small and mid-tier businesses can – and do – have enterprise requirements.
Which businesses rely on file transfers
I know through almost two decades of working in the MFT industry that it is a critical application for businesses. I don’t recall any scenario in which the uptime of MFT is trivial, or where it is not moving files that are considered sensitive.
At Axway, we know real-world reliance on MFT is economy-scale: ~6.5M vehicles, ~47,000 flights daily, and $700T in annual payments run on Axway-supported MFT flows.
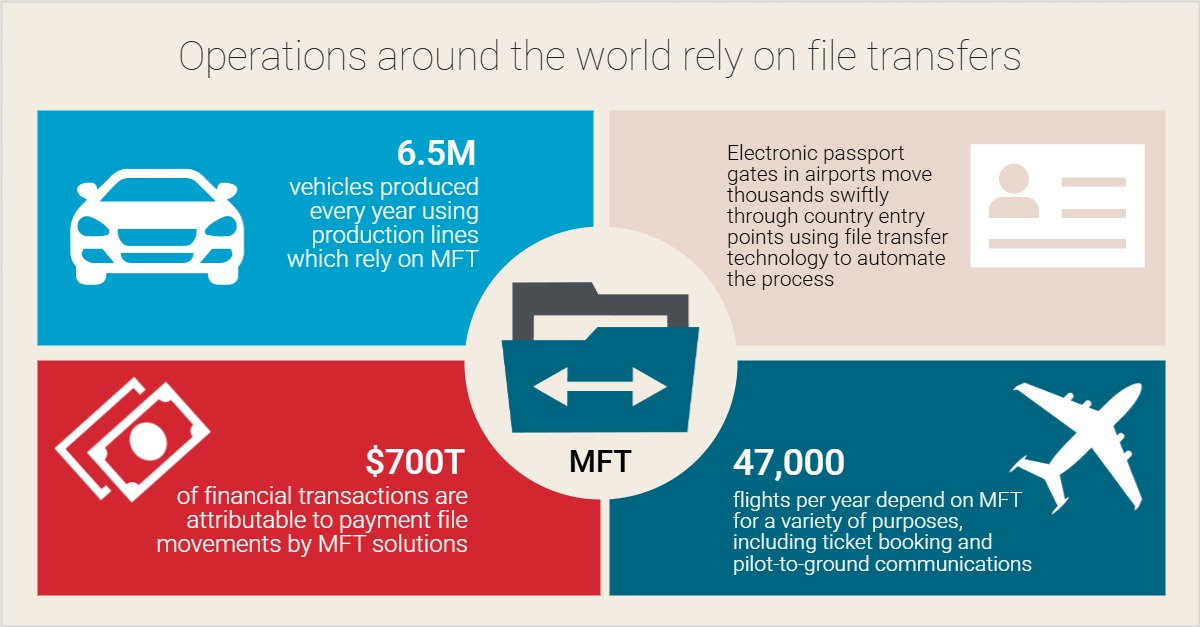
Why resiliency matters
But think further than the first layer of business requirements and think about how this impacts business relations, consumers, and everyday activities. Disruption goes beyond simply not being able to transact or deliveries being delayed.
Consider a relatable scenario. If you were booking a vacation on a travel website and you were unable to complete the booking, or the process was painfully slow, what would you do? For many, they would simply book with a competitor or an alternative website.
It is an easy conclusion to draw that for businesses, resiliency matters as it impacts their financial bottom line. But it also has impacts on competition, brand reputation, partner/supplier reputation, and even share prices in cases of significant disruption. All of which can have longer-tail effects.
For consumers and customers, disruption may have productivity effects. Additional time spent interacting with a website, booking services, and having to seek alternatives. In extreme circumstances, such as the example above in which electronic passport gates are affected, customers could be left without alternatives or subject to significant delays because of regression to manual processing.
What resiliency options exist for managed file transfer?
The short answer is: many. MFT is an industry awash with enterprise requirements due its criticality and, as a result, there are several options – traditional and new – available for improving resiliency.
Application-level high-availability
The more traditional option for managed file transfer solutions is that which is offered inside of the application itself. Either active-active or active-passive scenarios which support the addition of one or more application servers, either for redundancy or added capacity.
My experience with MFT solutions is that this remains the most common form of resiliency in place. But there are several aspects to consider:
- Cost of purchasing two or more software licenses or subscriptions.
- Whether the two solutions are hosted in the same data center, using shared resources, or in the same geographical location. A key consideration for resiliency is single points of failure – some of which exist outside of the application itself.
- The impact of dependent services being hosted on the application separately. Databases are a good example, and some database applications reserve large portions of the available system memory, which could have impacts on the availability of memory for the MFT application.
Cloud hosting and hypervisor services
The more contemporary flavor of resiliency option comes from the platforms in which the MFT solution is being hosted on itself. There are a plethora of virtualization and hypervisor cloud hosting platforms on offer, but it seems never a week goes by when I am not talking about AWS in some shape or form.
The benefit to platforms such as AWS are their sheer size and scope. Amazon has data centers in all corners of the world, meaning we that can address the geographical challenge by simply hosting two MFT solutions in two different regions. In addition to this, such services usually offer cold-site capabilities in which a secondary or tertiary service can be hosted in an offline state, ready to be brought online when required.
A challenge to consider with cold sites and their replication are RPOs (recovery point objective) and RTOs (recovery time objective).
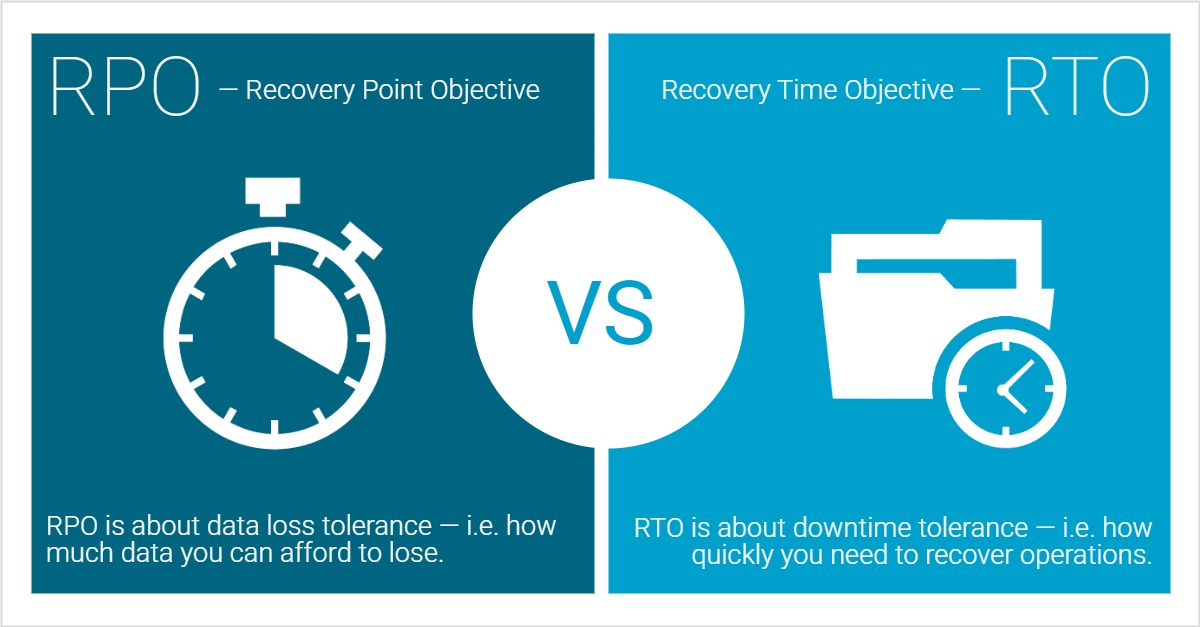
RPO and RTO address different aspects of resilience. When using cold sites, both must be taken into consideration and will affect decisions like backup frequency, infrastructure investment, vendor SLAs, and business impact analysis.
Containerization
Containerization typically goes together with cloud hosting, but there are inherent benefits to containerization which warrant being called out. In particular, the ability to create lightweight and scalable instances of MFT, which can be deployed and destroyed with little time.
This could be useful in environments where there are cost concerns with maintaining multiple concurrent MFT instances or cold sites; instead, allowing for the quick deployment of a new MFT container should the primary be lost or unavailable.
A key concern here is maintaining the image of the container. Each time the primary container is patched or updated, the same would need to be applied to the container image. Otherwise, that which is deployed could be using an unsupported or incompatible version, further impacting the service.
Other considerations for resiliency
Resiliency is often (incorrectly) synonymous with availability. While availability is of critical importance, as we have explored, it is not the only benefit of resilience initiatives. These include:
Improvement in patching and upgrade processes – both through zero-downtime updates or using multiple MFT applications. Where patching doesn’t impact availability, businesses are encouraged to patch more frequently as there is no downtime, shortening the time between patch release and patch application. Due to how heavily they rely on MFT, many businesses avoid patching due to downtime, which can leave systems open to disclosed vulnerabilities.
Improved throughput/capacity – where multiple MFT applications are available and files routed through them; they provide combinational throughput. This type of resiliency is resiliency to high loads, rather than availability challenges. High loads can lead to bottlenecks and slow throughput. From the perspective of a customer or a trading partner, slow throughput is just as problematic as downtime.
What leadership should remember about resiliency
Resiliency in MFT is about continuity of business outcomes in circumstances of failure and change. When the platform can withstand a host failure, a zone-level disruption, or a mid-day release without losing transfers, the business patches faster, isolates faults better, and spends less time in recovery mode.
The payoff isn’t just uptime; it’s protected revenue, stronger compliance posture, and steadier partner confidence – at the very scale where a few hours of disruption cascade into missed orders, delayed flights, or late payments.
My recommendation is to treat MFT accordingly: as a system whose resilience safeguards core promises to your customers and your regulators, every day that it quietly does its job.

Frequently Asked Questions
Why does resiliency matter if we already have high availability?
High availability is a facet of resiliency. High availability helps with assurances in instances where singular MFT applications are down or unavailable. Resiliency is a wider concept, encompassing the redundancy of dependent services, geographical spread, cold-sites, capacity and zero-downtime updates.
How does resiliency improve security?
When updates don’t require downtime, teams patch on schedule. That higher patch cadence shrinks exposure to actively exploited issues and lowers the odds that small misconfigurations or unpatched vulnerabilities become significant incidents.
Does moving MFT to the cloud automatically make it resilient?
No. Cloud gives you building blocks such as availability zones, managed storage, elastic compute. But you still need to design for fault isolation, state externalization, and safe change to turn those blocks into continuity and full resiliency.
Where do containers fit into resiliency?
Containers make instances disposable and fast to replace, which shortens recovery time and encourages immutable, repeatable releases. They don’t replace good state design or fault isolation, but they do make both easier to practice.
What should leadership measure to know resiliency is working?
Track business-level SLOs and operational health. For example, successful transfer rate, median/95th percentile transfer time, retries per partner, queue depth, RTO/RPO peak tests, and time-to-patch from advisory to production.
These tell you whether customers and partners experience continuity—especially on release days.