



1. Introduction
“Streamdata.io is a real-time cache proxy allowing you to poll JSON REST APIs and push updates to clients”. Ok, sounds great. Indeed, the features provided are exactly what you need but what is the impact on your performances? Here, we want to talk about performance, from the client, to the backend, with figures, charts and everything you will need to see the benefits of streamdata.io which are not only feature based, but that also come with amazing performance!
We are going to compare an API which will provide simulated market data standard architecture to the same API using streamdata.io. The comparison will focus first on the backend (information system) behavior under load and then on client latency.
2. Setup
2.1 The API: stockmarket
Java Servlet simulates a list of quotes updated every 20 seconds. Content is provided through a JSON REST API. The API will be polled every 5 seconds in our tests.
2.2 Standard architecture
Because we wanted to be fair and give a chance to the standard architecture, we decided to setup a proxy cache (Varnish) in front of the REST API. This will ensure enhanced performances and a more realistic architecture:
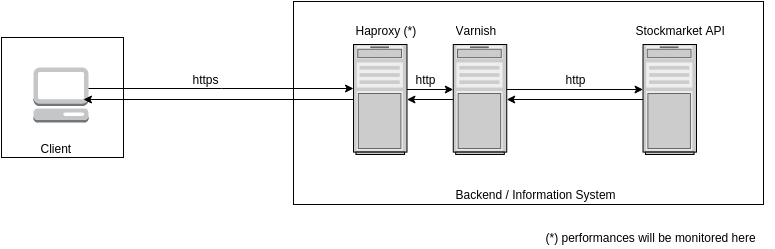
NB: As Varnish does not support SSL, we setup an haproxy in front of it in order to take care of SSL offloading. These are the recommendations from Varnish documentation.
2.3 Streamdata.io architecture
We dedicated a streamdata.io environment in order to perform this benchmark. If you want to use it on your own, streamdata.io is available as a SaaS in the cloud.
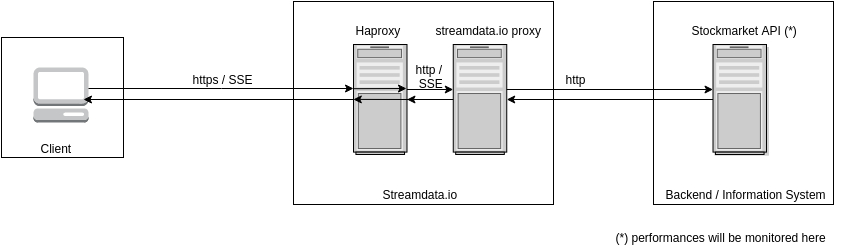
2.4 Client
We used Gatling for the client side of our tests. In addition to the classical http loadtest feature, Gatling has a great advantage of being able to do loadtests on SSE (Server-Sent Events). This is primordial for our streamdata.io architecture.
2.5 Hardware
The hardware used in our test is not intended to be extremely powerful because we are doing a comparison between two different architectures. The main point is that the comparison is done between identical hardwares.
Hypervisor : Proxmox cluster running on 4 x HP DL360-G6 (pmx1 to 4)
CPU: 16 x Intel Xeon E5530 @ 2.40 GHz (2 sockets)
RAM: 16 GB
Gatling : Virtual Machine using 8 CPU and 8 GB RAM
Stockmarket : Virtual Machine using 1 CPU and 1 GB RAM
HAProxy : Virtual Machine using 1 CPU and 1 GB RAM
Streamdata Proxy : Virtual Machine using 2 CPU and 2 GB RAM
Varnish : Virtual Machine using 2 CPU and 2 GB RAMAll these VMs are allocated on several Proxmox hypervisors inside the cluster.
Now, let’s start the bench!
3. CPU
3.1 Backend
This is a comparison of CPU usage with and without streamdata.io, during a 2 minute benchmark for 1000, 5000 and 10000 users. CPU is monitored at the entry point of the backend, that is haproxy (standard arch) or stockmarket API (streamdata.io arch).
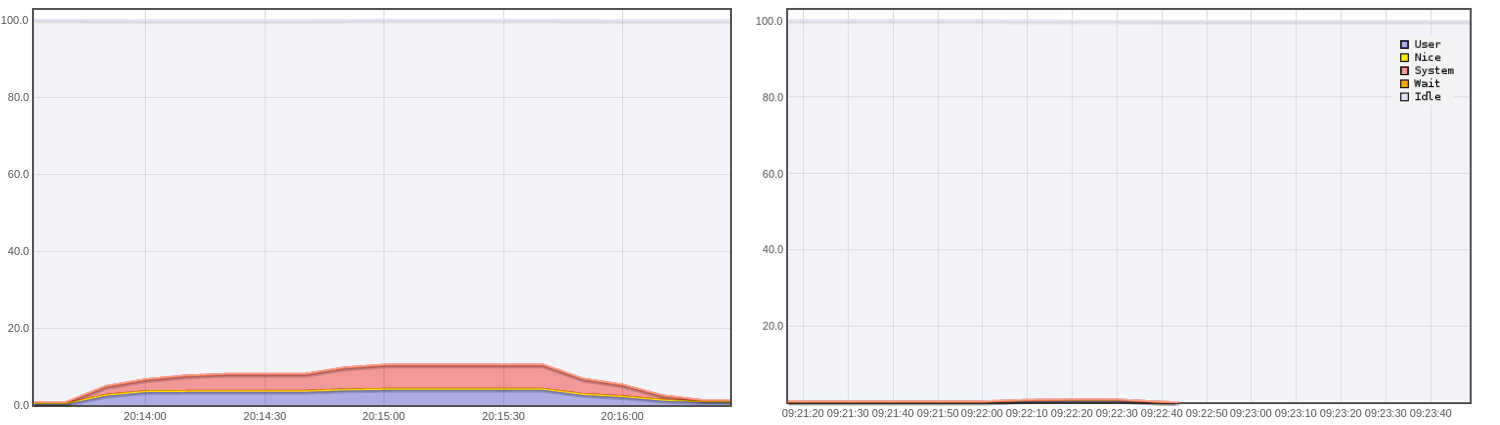
1000 users: CPU usage (%) for standard architecture (left) and streamdata.io architecture (right)
=> The CPU usage for the standard architecture is around 10%. No activity for streamdata.io architecture.
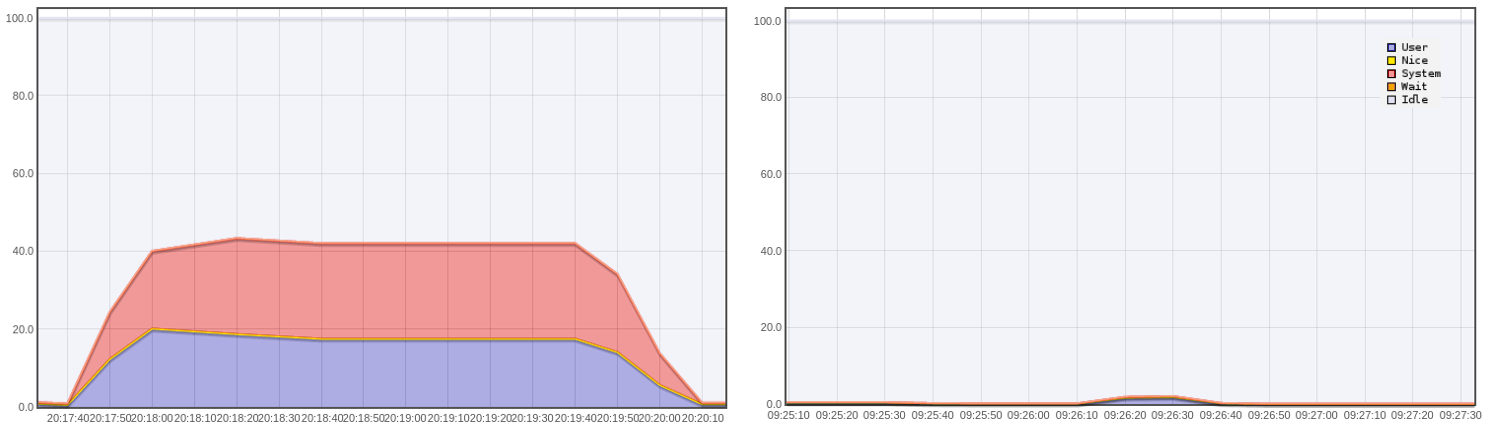
5000 users: CPU usage (%) for standard architecture (left) and streamdata.io (right)
=> The CPU usage for the standard architecture is around 40%. No activity for streamdata.io architecture.
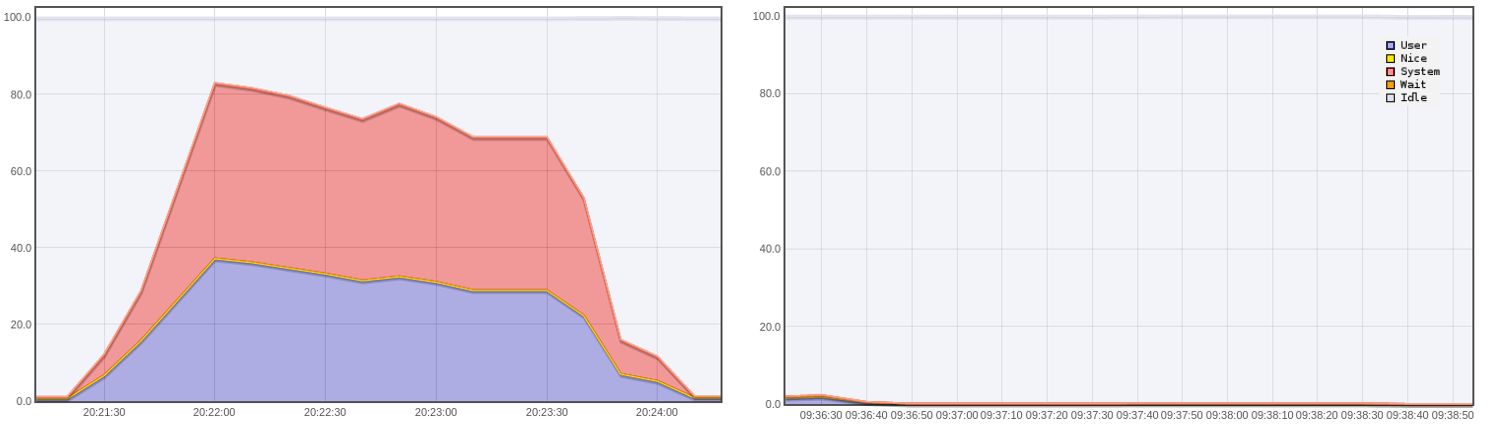
10000 users: CPU usage (%) for standard architecture (left) and streamdata.io (right)
=> The CPU usage for the standard architecture is around 80% with peaks to 100% which cannot be seen on the graph. We are reaching the limits of the standard architecture. Still no activity for streamdata.io architecture.
Well, I guess streamdata.io will allow you to downgrade your productuion servers and save money!
What is taking so much CPU on a standard architecture? The first reason is quite obvious, the backend is directly handling thousands of users whereas with streamdata.io, the load is handled by streamdata.io and the backend receives only one polling every 5 seconds. The response is then cached and the update is sent to the users. The second reason is SSL. The standard architecture has to handle thousands of connections every 5 seconds. Even when reusing connections, this is still something resource-consuming.
On streamdata.io, the https connection (including SSL handshake) is established once per client. The connection is then kept open to push data when updates are available (Server-Sent Events).
3.2 Client
Just a few words to say that we also monitored our load test client during the benchmarks. The CPU resources involved on standard architecture are much bigger than on streamdata.io (thousands of requests every 5 seconds versus thousands of connections established once for all). The topic deserves deeper investigation, but it seems to show something expected, that is, establishing one SSE connection and processing only JSON-Patches is less resource-consuming than polling at regular interval. This is also good news for the battery as explained in this study. Think about limited resource hardwares such as mobile devices!
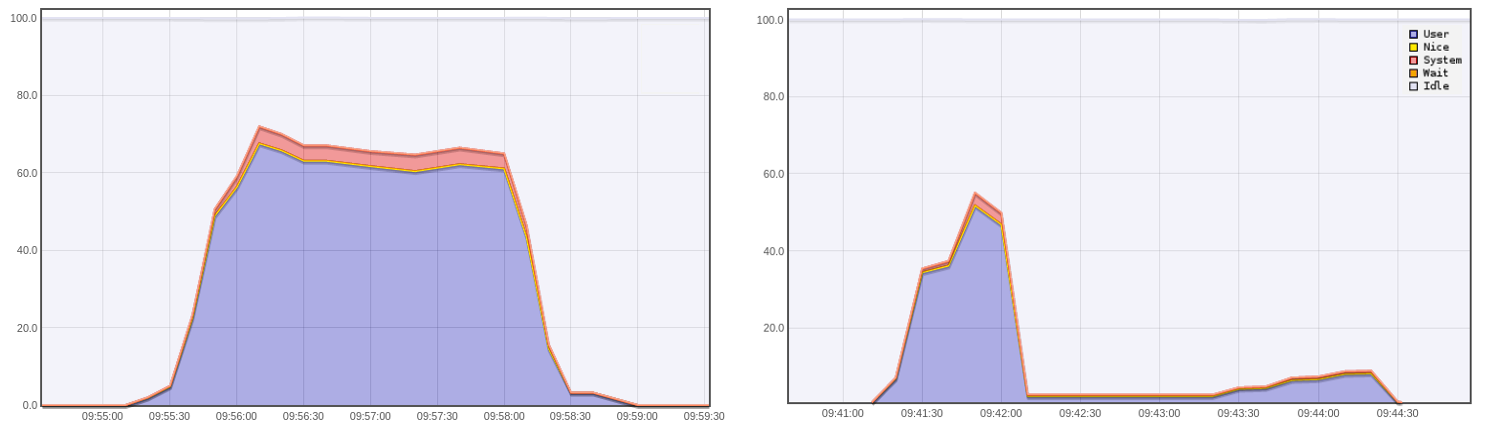
10000 users, 2 minutes test: Test client (Gatling) CPU usage (%) for standard architecture (left) and streamdata.io (right)
4. Bandwidth
This time, we focus on the bandwidth usage with and without streamdata.io. The Bandwidth is monitored at the entry point of the backend, that is haproxy (standard arch) or the stockmarket API (streamdata.io arch). The figures below show the bandwidth usage (iftop) during a 2 minutes benchmark.
Cumulated Bandwidth usage
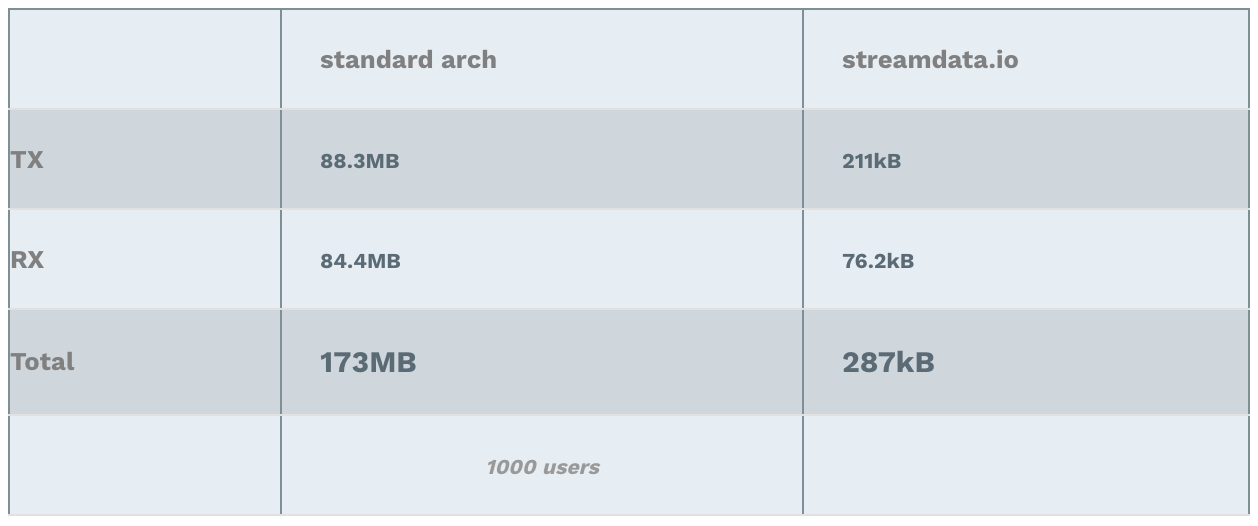

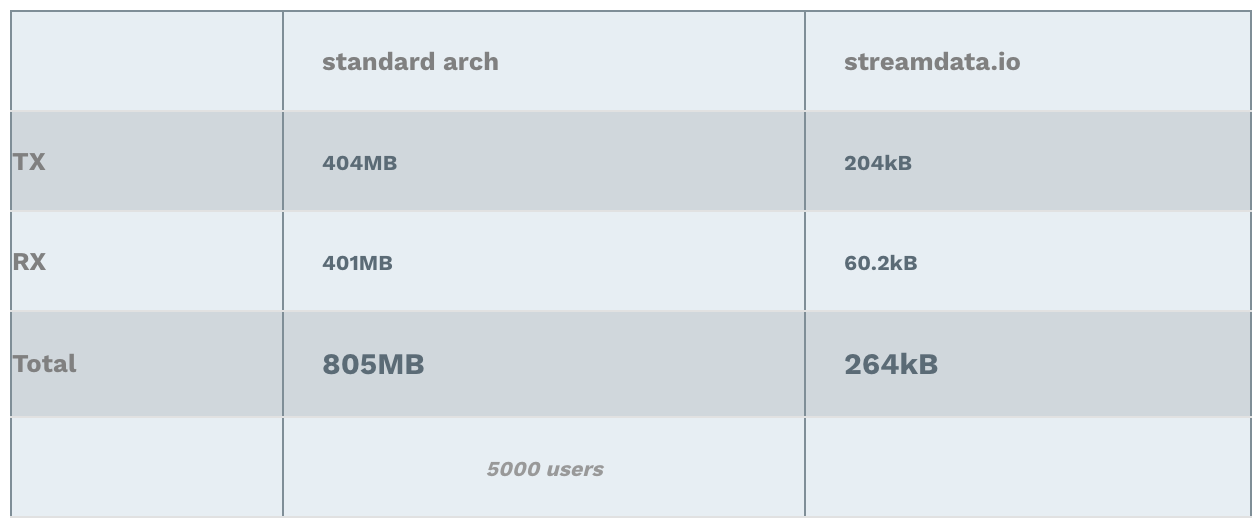
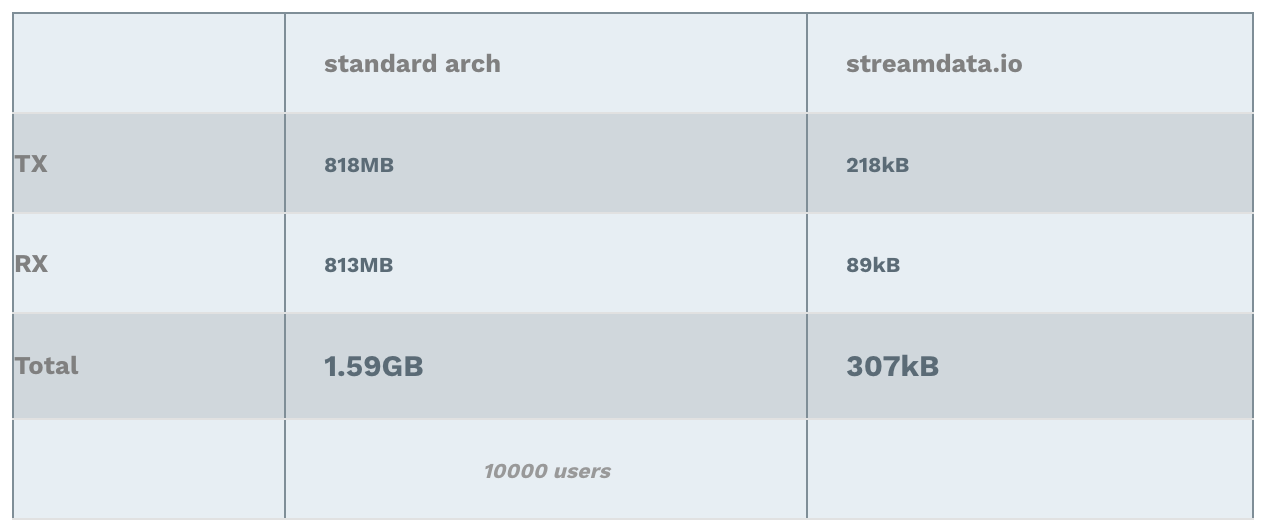
Note: RX stands for Received (download), TX stands for Transmitted (upload).
Bandwidth Usage Peak
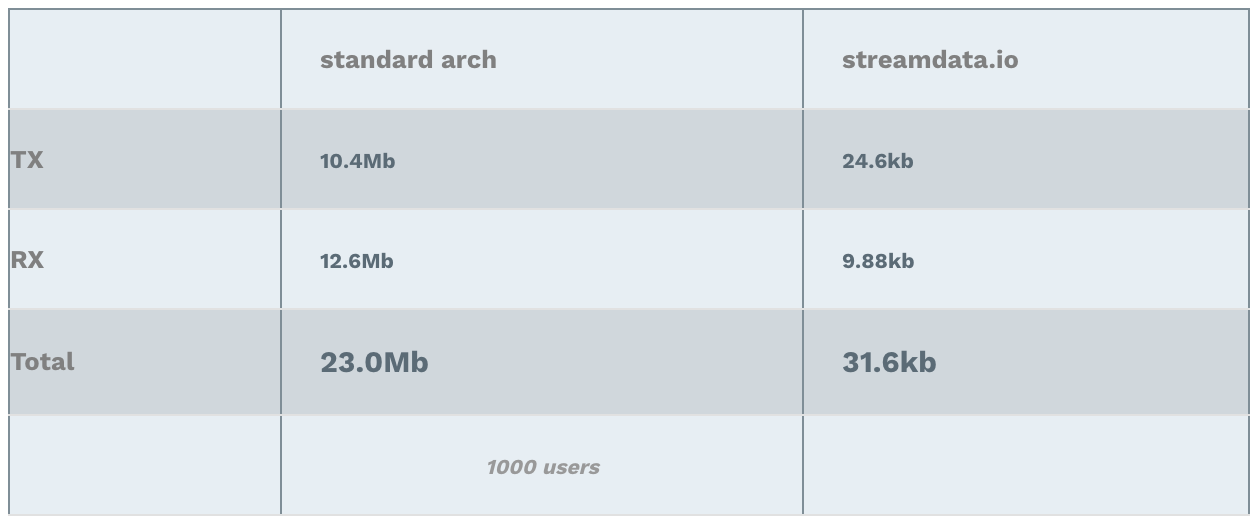

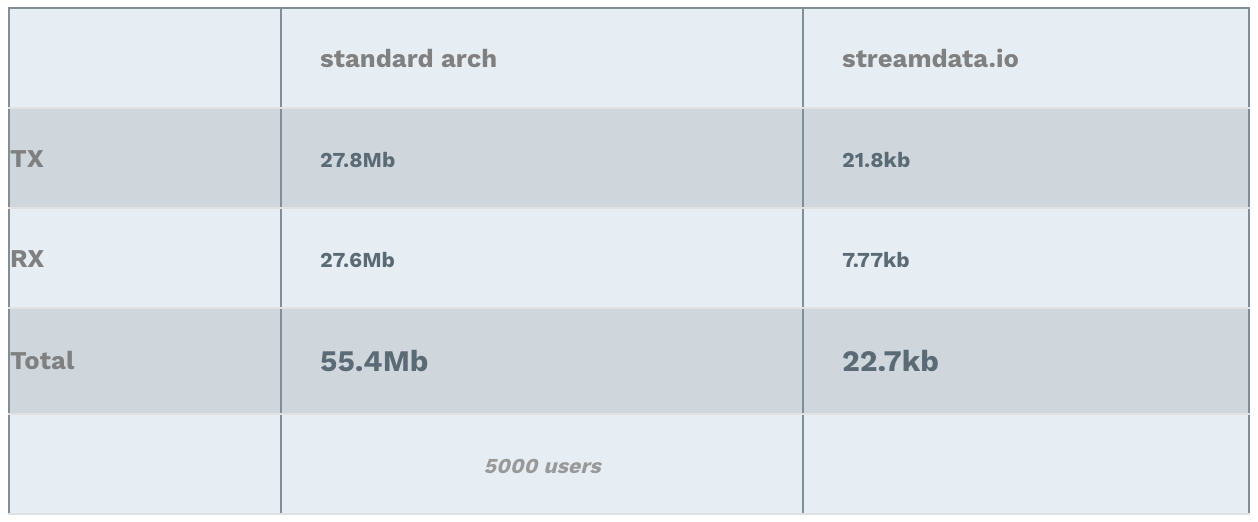

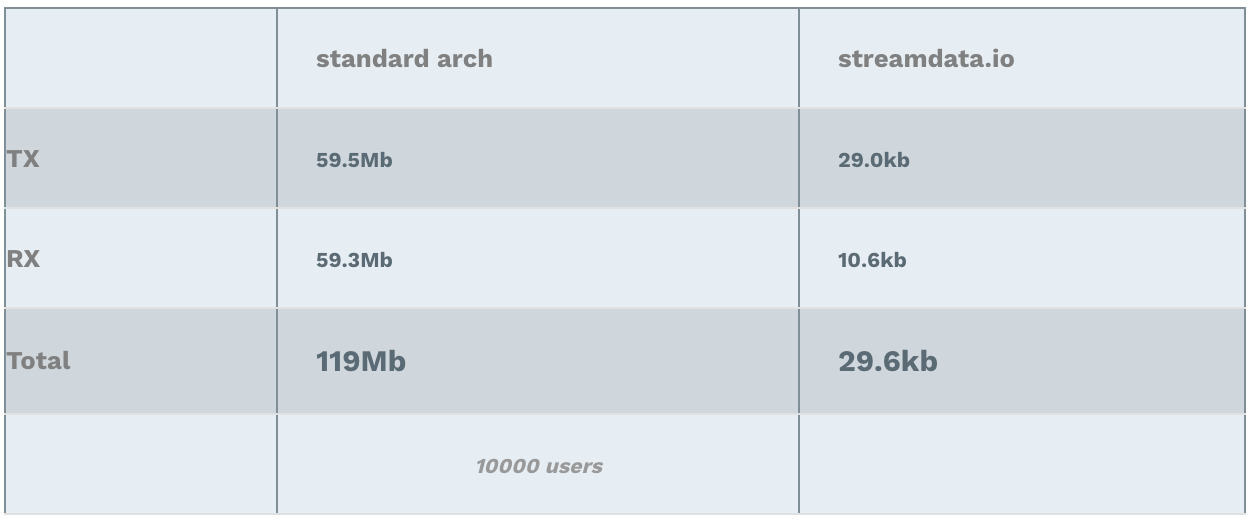
Furthermore, since streamdata.io sends updates containing only the difference between the two pollings, it reduces the bandwidth usage on our backend, but also on the client side! Note: RX stands for Received (download), TX stands for Transmitted (upload).
Note (bis): iftop has no filtering here, which explains why the measures are not exactly accurate. They are taken for the entire network interface. That does not compromise the results interpretation.
Why these amazing results ;-)? Again, in one case, the backend is handling the load of all clients. In the other case, it is streamdata.io which sends only 1 request every 5 seconds to the API. Hence, the interpretation of the results is straight forward. The data transferred with streamdata.io architecture is more or less always the same: a few kilo bytes => nothing!
5. Memory
No need to report something here. The memory used in both architectures is not an issue nor a bottleneck at anytime.
6. Network Latency
This is quite a touchy topic. The comparison is hard to do since there is a change of paradigm (request/response vs. real time push). There are some ways to make a comparison, but we will not go into the details in this post (that might be a topic for another post ;)).
In short, standard architecture allows you to measure easily when you start a request and when you receive the response. On the other hand, streamdata.io latency figures will have to take into account, polling start (no client request), diff computation, data pushed to client when there is a diff, no data pushed to client when there is no diff. Indeed, this processing portion will introduce a bit of latency compared to the standard architecture, but this is the price you pay if you want to benefit from streamdata.io (awesome) features. In addition, this short post demonstrates that it will help you to reduce latency at another level.
We assume that a very good response time is below 1 sec and an ideal response time is below 500ms.
For both architectures, we observed on our benchmark environment that the 95th percentile (yes, percentile! you will find numerous studies on percentile vs. mean) stays below 1 second. Tests were performed up to 10000 users. Results cannot be strictly compared for the reasons explained above, but the standard architecture seems to show better network latency although streamdata.io architecture does not impact end user perception.
In addition, if we consider a mobile application in 3G, the response times will be slightly worse for standard architecture because the latency introduced by 3G will be introduced at every polling (connection initialization, handshake) whereas it is done only once with streamdata.io architecture.
Hence, we can state that latency is preserved with streamdata.io.
7. Conclusion
The benefits are straightforward. Using streamdata.io implies no cpu usage, no bandwidth consumption and improved latency .
I can already hear some of you “Why should I care? I do not own nor operate the backend, I just write applications using someone else’s API.”. Yes, you have developed an awesome application, but since it is awesome, a lot of people will start using it and you will quickly deteriorate the performances of the backend (if you don’t get banned), which means deteriorated user experience on your own application. Moreover, streamdata.io also enhances performances on the client side. It allows you to get a reactive UI and application, realtime updates, and not to worry anymore about the network connection management.
Now that you have concrete figures to rely on, the best thing to do is to try it out!