


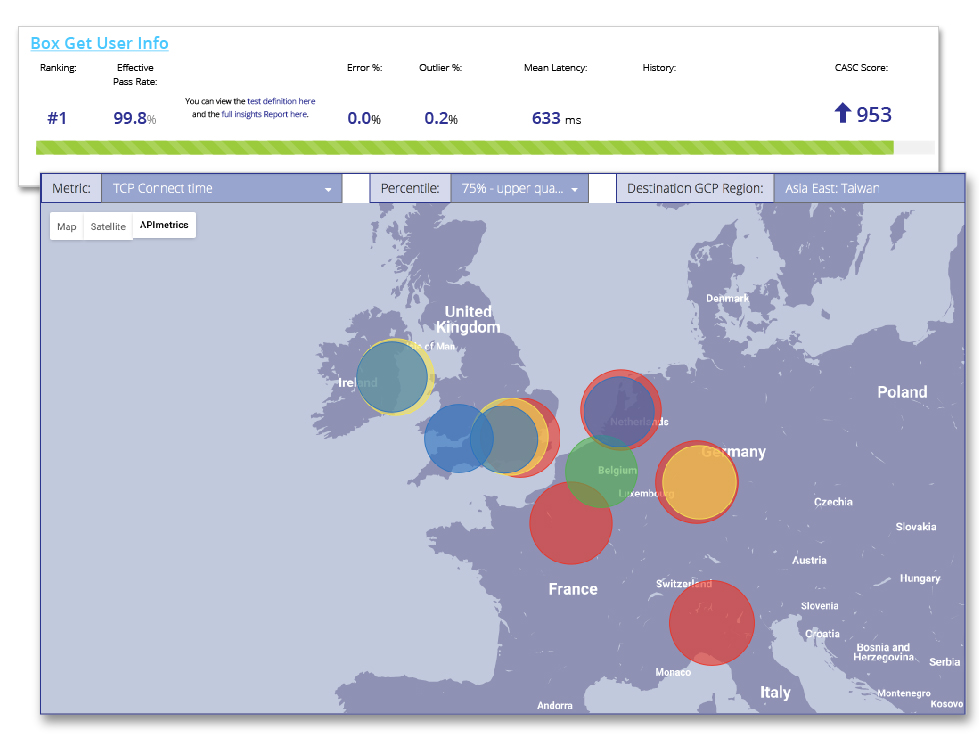
We were exchanging emails with the APIMetrics team this week, discussing the challenges that come up when monitoring APIs. We are working through the different ways in which we can create real-time streams of data from monitors that APImetrics has setup, and one of the challenges you encounter when monitoring API infrastructure at scale is the ability to sift through large volumes of signals to understand what truly matters. When you are monitoring a large number of APIs, depending on the approach, the overall health of the API, and the clients that are consuming resources, you are likely to experience regular waves of HTTP status codes to sort through looking for the responses that actually matter and mean something. We are thinking about how cutting HTTP status code noise will make API monitoring streams more intelligent.
As we were discussing this, the topic of machine learning (ML) came up, and how we can use it to help make sense of the potentially huge amounts of HTTP status codes we’ll have to process. Allowing us to not respond to individual signals, but groups or patterns of signals, and make API monitoring a little more intelligent, reduce the chances we’ll miss some important monitoring updates. Using machine learning to do the heavy lifting of looking through large amounts of data, and rely on humans to do the responding when relevant patterns are uncovered. If you rely on humans to look at every signal returned they are inevitably going to burn out, miss patterns, and become blind to much of what is returned. By leaning on ML to look through the volume of data, we can lighten the load for the human, and help them be a little more efficient in what they deliver.
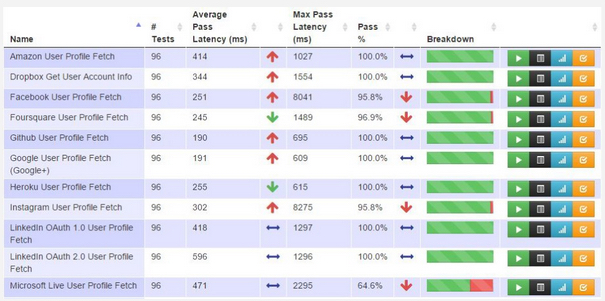

Knowing the state of things at some of the API providers we are tracking on we think the important first step here is getting API providers monitoring their infrastructure. We are fully aware that many do not. Once we have 100% coverage of the API surface area, then I think we can begin to think about setting up streams on top all, or specific groups of monitors. Then once we have the data gathered, providing us a better picture regarding what is going on, then hopefully we can intelligently begin thinking about what types of ML models should be applied. Discuss what exactly is the noise when it comes to monitoring, then begin to train the models to filter out the noise. I’m guessing it will take several attempts before we can get a cleaner stream of API monitoring data. I’m also guessing it will take different approaches depending on the design and overall health of API but is something that will be worth doing, because of the high quality, well trained ML models that could emerge out of the effort.
Streamdata.io is partnering with APImetrics to better understand what is possible when you begin streaming your API monitoring data. We are also working to understand the positive impact API monitoring can have on being able to deliver more reliable streams because the underlying APIs are healthier. Ideally, all web APIs have an API monitoring layer using a service like APImetrics, as well as a potentially more real-time layer, allowing consumers to choose between the lower speed request and response model, as well as the higher speed version by streaming data using Server-Sent Events (SSE).

